후우... 왔습니다. Transformer 이 친구 예전에 한번 봤는데 저한텐 굉장히 어려웠었어요. 그래서 관련 개념만 찍먹하고 넘어가려고 했는데 논문 리뷰 스터디에서 발표 주제를 정하는데 뭔가.. 기본이 중요하지.. 라는 객기를 부려서 이 논문을 선택하게 되었습니다.
워낙 유명한 논문이니만큼 조심해야겠죠...? ㅋㅋㅋㅋㅋ
한번 해볼게요!
읽고 난 후
확실히 어려운 논문이었습니다. 사실 강의 3개 + 지인에게 물어보기 등등 해도 아직 이해하지 못한 부분이 꽤 많네요...
신기술의 근간인만큼 굉장히 중요한 논문이라고 생각하며 이제 앞서 Transformer를 구현하신 분의 블로그를 따라 구현을 시작하려고 합니다. 화이팅...!
Abstract
기존 모델은 순환형이나 합성곱 신경망을 기반으로 인코더와 디코더를 수행했는데 병렬화가 안된다는 문제점을 가지고 있었습니다. 그래서 본 논문은 Transformer라는 새로운 모델을 제시하며 Attention만 사용한다고 이야기합니다.
Introduction
기존 순환 모델은 RNN을 사용하는 방식으로 매커니즘상 병렬처리를 할 수 없게 합니다. Attention Machnism은 입력 또는 출력 시퀀스 내에서 거리에 상관 없이 종속성(유사도)을 모델링할 수 있게 해줍니다. 그리고 보통 RNN과 결합하여 사용하게 됩니다.
그러나 본 논문에서는 Recurrence 완전 배제하고 오로지 Attention을 사용한 Transformer 아키텍처를 제안합니다.
Background
기존 모델에서 입력값의 길이가 길어질수록 연산의 수가 위치 간의 거리에 따라 선형적으로 혹은 로그함수적으로 증가하게 됩니다. 이런 시도는 Extended Neural GPU, ByteNet, ConvS2S에서 그렇습니다.
Transformer는 이런 계산을 상수 개의 연산으로 줄이는 대신 attention 가중치가 부여된 위치를 평균화함으로 효과적인 해상도가 감소하는 비용을 지불하는데 이걸 Multi-Head Attention 을 통해 상쇄합니다.
트랜스포머 모델에서는 입력 또는 출력의 임의 위치들 간의 관계를 설명하는 데 필요한 연산 수를 상수로 유지합니다. 즉, 어떤 두 위치가 서로 얼마나 떨어져 있던지 상관 없이 같은 수의 연산으로 그들 사이의 관계를 계산할 수 있다는 것입니다. 이는 이전의 ConvS2S나 ByteNet 같은 모델들에서는 위치 간의 거리에 비례하여 필요한 연산 수가 늘어나는 것과 대조적입니다.
효과적인 해상도가 감소한다는 것은, 트랜스포머가 입력 데이터의 세부 사항이나 미묘한 차이를 덜 파악하게 됨을 의미합니다. 이는 어텐션 메커니즘에서 모든 입력 위치의 가중치를 평균화하기 때문에 발생하는 문제입니다. 이 평균화 과정은 중요한 정보가 들어있는 위치와 그렇지 않은 위치가 동일하게 취급될 수 있음을 의미합니다. 그 결과, 중요한 위치의 정보가 상대적으로 희석되어, 그 위치의 '해상도'가 감소하게 됩니다.
그래서 이 단점을 극복하기 위해 트랜스포머는 Multi-Head Attention이라는 기법을 사용합니다. 이 기법은 동일한 입력에 대해 여러 attention 메커니즘을 병렬로 적용하여 각기 다른 관점에서 데이터를 해석하고, 이렇게 얻은 정보를 결합하여 더 풍부한 해석을 제공합니다. 이로써 attention 가중치 평균화로 인한 해상도 감소 문제를 상쇄하게 됩니다.
Model Architecture
Transformer는 Endoder-Decoder architecture를 따른다고 합니다.

3.1 Encoder and Decoder Stacks
Encoder
이 문장은 Transformer 모델의 내부 아키텍처에 대해 설명하고 있습니다. Transformer의 핵심 구성 요소는 '하위 레이어(sub-layer)'라고 불리는 여러 레이어로 이루어진 '인코더'와 '디코더'입니다. 각 하위 레이어는 주로 '셀프 어텐션(self-attention)' 메커니즘과 '피드포워드 신경망(feed-forward neural network)'으로 이루어져 있습니다.
이러한 하위 레이어 각각 주변에 '잔차 연결(residual connection)'이라는 기법이 적용됩니다. 잔차 연결은 입력 데이터를 레이어의 출력에 바로 추가하는 방식으로, 그래디언트 소실(vanishing gradient) 문제를 완화하는 데 도움이 됩니다. 이런 방식으로 하위 레이어의 학습이 안정화되며, 심층 신경망에서의 효과적인 학습이 가능해집니다.
Decoder
트랜스포머의 디코더 부분에 대한 설명입니다. 디코더는 또한 여러 레이어로 구성되며, 각 레이어에는 세 개의 하위 레이어가 있습니다: 셀프 어텐션 레이어, 인코더-디코더 어텐션 레이어, 그리고 피드-포워드 신경망입니다.
인코더-디코더 어텐션 레이어는 디코더가 인코더의 출력에 어텐션을 수행하게 해줍니다. 이를 통해 디코더는 인코더의 전체 출력에 접근할 수 있습니다.
디코더의 셀프 어텐션 레이어는 수정되어 이후 위치에 어텐션을 주는 것을 방지합니다. 이는 디코더가 현재 위치 이전의 정보만을 기반으로 예측을 수행하도록 하는 역할을 합니다. 이는 시퀀스 예측 작업에서 필수적인 조건으로, 예를 들면 문장을 번역하는 작업에서, 단어를 번역할 때 해당 단어 이후의 단어 정보를 사용해서는 안되는 것과 같습니다.
이렇게 각 하위 레이어를 거치고 나면, 마찬가지로 잔차 연결과 레이어 정규화가 적용되어, 디코더 레이어의 최종 출력이 생성됩니다.
3.2 Attention
어텐션 함수는 쿼리와 일련의 키-값 쌍을 출력으로 매핑하는 것으로 설명될 수 있습니다. 여기서 쿼리, 키, 값, 출력은 모두 벡터입니다. 출력은 값들의 가중치 합으로 계산되며, 각 값에 할당된 가중치는 해당 키와 쿼리의 호환성 함수를 통해 계산됩니다.
3.2.1 Scaled Dot-Product Attention
2가지 종류의 Attention 중 Dot-Product Attention
실제로 점곱 어텐션은 가산식 어텐션에 비해 연산이 더 빠르고 공간 효율적입니다. 이는 행렬 연산에 최적화된 코드를 사용하여 구현할 수 있기 때문입니다. 이러한 이유로, 트랜스포머 모델에서는 점곱 어텐션, 특히 그 변형인 스케일드 닷-프로덕트 어텐션(scaled dot-product attention)이 사용됩니다.
dk 값이 작을 때 두 가지 메커니즘(가산식 어텐션과 점곱 어텐션)은 유사하게 작동하지만, dk 값이 크게 증가할 때 가산식 어텐션이 스케일링 없는 점곱 어텐션보다 성능이 더 좋습니다[3]. 우리는 dk 값이 크면, 점곱의 크기가 커져서 소프트맥스 함수가 극도로 작은 기울기를 가진 영역으로 밀리게 된다고 생각합니다. 이 효과를 상쇄하기 위해, 점곱의 결과를 1/√dk로 스케일링합니다.
이 설명은 점곱 어텐션에서 스케일링 요소를 도입하는 이유를 설명합니다. 이는 어텐션 메커니즘에서 각 차원의 키(key)와 쿼리(query)의 점곱이 클 경우, 이들의 합계가 소프트맥스 함수의 입력으로 사용될 때 이 함수의 기울기가 극단적으로 작아지는 현상을 방지하기 위함입니다. 이로 인해 역전파(backpropagation) 시 기울기 소실(vanishing gradient) 문제가 발생할 수 있습니다. 이를 완화하기 위해 점곱 어텐션에서는 각 차원의 점곱 결과를 키와 쿼리의 차원 수의 제곱근으로 나누는 스케일링을 적용합니다.
Softmax Function
손실 함수에서 사용되는 소프트맥스 함수는 입력 벡터를 확률 분포로 변환하는 데 사용됩니다. 이 변환은 각 입력 값의 지수 함수를 계산하고, 이를 모든 입력 값의 지수 함수의 합으로 나눔으로써 이루어집니다.
입력 값이 매우 크면, 이 지수 함수의 값은 매우 크게 됩니다. 그리고 이는 소프트맥스 함수의 출력 값 중 하나가 1에 매우 가깝고, 나머지 값들은 0에 매우 가까워짐을 의미합니다. 이러한 현상을 "소프트맥스 함수의 포화(saturation)"라고 부릅니다.
이 문제는 역전파에서 심각한 문제를 일으킵니다. 출력 값이 1 또는 0에 가깝다면, 그 기울기는 거의 0이 됩니다. 따라서 그라디언트가 역전파되는 동안 이런 기울기가 곱해져서 전달되면, 앞단의 뉴런들은 거의 업데이트 되지 않게 됩니다. 이를 "기울기 소실 문제(Gradient Vanishing Problem)"라고 부릅니다.
따라서, 점곱의 결과가 너무 크게 되는 것을 방지하고 소프트맥스 함수가 포화되는 것을 방지하기 위해, 점곱의 결과를 차원의 수의 제곱근 값으로 나누는 것입니다. 이로 인해 모델의 학습이 더 안정적이고 효율적이게 됩니다.
3.2.2 Multi-Head Attention
다른 positions에 있는 다른 representation들에서 얻은 정보를 모델이 같이 참조할 수 있도록 해주는 게 Multi-head attention이다.

Multi-head attention은 input embedding을 dmodel/h만큼 나누고 attention을 적용시키기 때문에 각각의 head 는 줄어든 dimension을 가지고 연산을 진행하기 때문에 single attention head with full dimensionality와 동일한 연산을 가진다고 이야기 합니다.
3.2.3 Applications of Attention in our Model
총 3가지의 multi-head attention이 존재합니다.
1. "encoder-decoder attention" layers : encoder의 output으로 keys와 values를 가져옵니다. input인 Query는 이전 디코더 계층에서 옵니다. 이렇게 하면 디코더의 모든 위치가 입력 시퀀스의 모든 위치를 주시 할 수 있게됩니다.
2. self-attention layers in encoder : Q,K,V 모두 이전 encoder 층에서 오며, 각 위치는 이전 layer에서 모든 층을 주시할 수 있습니다.
3. self-attention layers in decoder : 디코더에서도 인코더와 마찬가지로 디코더 내의 각 위치가 해당 위치 + 이전의 모든 위치를 주시 할 수 있도록 합니다. 출력 시 디코더에서 정보의 흐름이 왼쪽으로 가는 걸 방지해야하며 자동 회귀 속성을 보존해야 합니다. 이를 위해 scaled dot-product attention을 making out 으로 처리해줍니다.
# 주시 : 모델이 해당 위치에서의 정보를 고려하고 그 정보를 통해 출력을 생성하거나 수정할 수 있다는 의미
# Auto-regressive property : 자동 회귀 속성 - 출력 시퀀스를 한 번에 한 요소씩 생성 ( 각 출력 요소가 이전에 생성된 요소에만 의존한다는 것을 의미 )
3.3 Position-wise Feed-Forward Networks
#The purpose of the layer is to introduce non-linearity and increase the model's capacity to capture complex patterns in the data.
data의 patterns를 찾아내서 inference를 함
3.4 Embeddings and Softmax
학습된 Embedding 은 input, output tokens을 dmodel dimension으로 변환하는데 사용되고 학습된 linear transformation과 softmax function은 decoder output을 예측된 다음-token 확률로 변환하는 데에 사용된다. 이때 root-dmodel을 곱해서 성능을 증가시킨다.
3.5 Positional Encoding
Transformer는 recurrence를 사용하지 않기 때문에 상대적이거나 절대적인 위치에 대한 정보를 부여해야만 한다.
dimension은 dmodel과 같다.
본 모델에서는 sine, cosine functions 를 사용한다
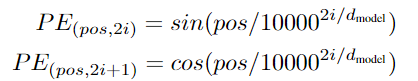
pos는 위치, i 는 dimension이다
positional encoding은 정현파와 상응한다
제 기억 상으로 sin과 cos function 값을 주면 위와 같은 어떤 패턴이 존재해서 컴퓨터가 각 sequence의 순서를 파악할 수 있다고 하는 거 같습니다!
4 Why Self-Attention
현존하는 recurrent와 convolutional layers를 self-attention과 비교하면서 왜 self-attention이여야 하는지에 대해서 이야기해줍니다. 선택한 3가지 이유에 대해서 이야기하고 알려줍니다.
1. 층마다 전체 연산 복잡도
2. 병렬처리 될 수 있는 연산의 양(필요한 최소 연속 연산 수로 측정 - 최소 연속 연산 수가 많을수록 병렬처리 이점을 얻기 어려워진다고 합니다)
3. network에서 긴-범위 사이에서 경로 길이입니다. 음.. 이거 말고 서로 다른 계층 유형으로 구성된 네트워크에서 입력과 출력 사이의 최대 경로를 비교하는 것이 중요하다 - 장기 의존성 문제를 해결 할 수 있다
그래서 계산 성능을 향상시키기 위해 긴 sequences라도 모든 position에 집중하기보다 특정 task에 조정된 r 근처에 있는 size로 sequences를 제한 할 수 있다. <sequences 길이가 짧을수록 학습이 더 잘되기 때문에>
어텐션 헤드(attention head)는 어텐션 메커니즘이 각각 주목하는 부분을 나타내며, 이러한 헤드들은 서로 다른 작업을 수행하도록 학습되는 것으로 보입니다. 더불어, 많은 어텐션 헤드들이 문장의 구조와 의미에 따라 행동하는 것으로 보여, 언어의 구문적 및 의미적 요소를 학습하고 이해하는데 중요한 역할을 하는 것으로 나타났습니다
Training
5.1 Training Data and Batching
이떄 WMT Workshop on Machine Translation 데이터셋을 사용했다.
머신 번역 연구에서 널리 사용되는 benchmark dataset이다. 여러 언어 쌍에 대한 대량의 병렬 텍스트를 포함하고 있으며, 이로 인해 다양한 머신 번역 모델의 성능을 평가하고 비교하는데 이상적인 환경을 제공합니다.
대량의 데이터, 다양한 언어 쌍, 벤치마킹(다른 최신 모델과 성능을 직접 비교할 수 있다)
5.2 Hardware and Schedule
8 NVIDIA P100 GPUs 사용 + base models 를 학습시키는 데 12시간, big model을 학습시키는데 3.5일이 걸렸다고 합니다.
5.3 Optimizer
warmup 기법을 사용 - 학습 초기에 학습률을 점진적으로 증가시키고, 일정 단계 이후에는 학습률을 점차 감소시키는 방식입니다. 해당 공식은 아래와 같습니다.

학습률은 훈련 스텝이 warmup_steps에 도달할 때까지 선형적으로 증가하고, 그 이후에는 스텝 수의 역제곱근에 비례하여 감소합니다. 이렇게 하면 초기에는 학습률이 빠르게 증가하여 모델이 빠르게 학습하고, 이후에는 학습률이 천천히 감소하여 모델이 안정적으로 수렴하게 됩니다.
5.4 Regularization
3가지 regularization을 사용합니다.
Residual Dropout : 여러 곳에 적용했습니다.
Label Smoothing : 이게 뭐냐면 ont hot encoding처럼 0,1로 수를 제한하지 않고 그 언저리에 값을 줘서 모델이 분류를 더 넓게 할 수 있도록 하는 기법
Result
6.1 Machine Translation
Transformer 모델을 훈련할 때 WMT 데이터셋을 사용한 이유는 다음과 같습니다:
대량의 데이터: WMT 데이터셋은 대량의 병렬 텍스트를 제공합니다. 이런 대규모 데이터는 모델이 충분한 학습 데이터를 확보하고, 다양한 언어 패턴을 학습하며, 결과적으로 더욱 정교한 번역 성능을 발휘하게 합니다.
다양한 언어 쌍: WMT 데이터셋은 다양한 언어 쌍의 데이터를 제공합니다. 이는 모델이 여러 언어 간의 번역을 학습하고, 다양한 언어 환경에서도 성능을 평가하고 향상시킬 수 있도록 합니다.
벤치마킹: WMT는 머신 번역 모델의 성능을 평가하고 비교하는 공식적인 벤치마크 역할을 합니다. 이 데이터셋을 사용하면, Transformer의 성능을 다른 최신 모델과 직접 비교할 수 있습니다.
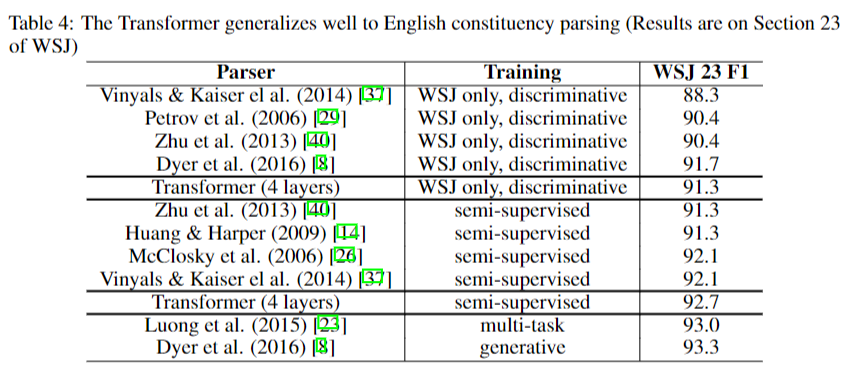
WSJ 데이터셋을 이용해서 성능을 Test한 결과 위와 같이 SOTA를 갱신했고 English Constituency Parsing도 SOTA라고 합니다.
7. Conclusion
Transformer 최고!
그리고 추후 modalities 또한 Transformer에 적용되면 좋겠다. 끝
Reference
참고 블로그 : https://eliza-dukim.tistory.com/40
[WK07-Day031][21.09.14.Tue] Transformer 주요 내용 요약 및 구조 개선에 대한 후속 연구, 논문 선정 팁
Intro 이번주는 명훈님 논문 읽기 모임 내용 + 강의 및 과제 내용 + 멘토링 논문 읽기로 계속 진행함 NLP 논문 읽기 모임 - Transformer 피어세션 - Transformer 논문 읽기와 강의 내용을 따로 정리하지 않고
eliza-dukim.tistory.com



댓글