읽고 난 후
Transformer 논문이 발표되기 전 Attention 개념을 적용시켰다는 것이 놀라웠습니다.
Abstraction
기존 NMT(Neural Machine Translation) 은 고정된 길이의 vector를 사용해서 병목현상이 발생 그래서 긴 문장에 대한 번역 성능이 좋지않다.
그래서 decoder에서 하나의 결과를 만들어 낼 때마다 입력문장을 순차적으로 탐색하고 가장 관련있는 영역을 적용해서 다시 target 문장을 만든다. 그래서 가변적인 context vector 생성이 가능해진다.
- 이때 Attention에 대한 개념이 등장한듯 싶습니다.
RNN Encoder-Decoder
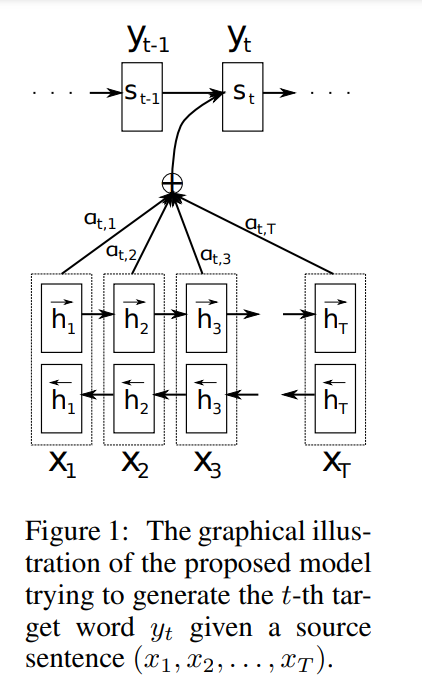
Encoder : 입력값 Xt 에 대해서 ht를 순,역방향으로 구하고 이걸 concate 시킵니다. 이걸 ht로 decoder에 넘깁니다.
Decoder : 먼저 예측을 하나씩 때리는데 이때 가장 관련 있는 영역을 적용 시킵니다.
ht 값으로 si 를 구합니다 여기서 ht, si는 encoder, decoder의 hidden state 값을 의미합니다.
그래서 si 값을 구하고 이것과 ht를 모델 a에 넣어서 얼마나 관련이 있는지에 대한 energy(score) 값을 구합니다.
이 e 값으로 aij 를 구하는데 이는 가중치를 의미하며 attention 과 동일 합니다. 이 attnetion 값과 ht를 곱해서 최종 context vector ci를 구한 뒤 최종 target 값을 생성합니다.
이때 새로운 부분은 end to end 같이 번역과 정렬(input 값과 target 값이 대응되는 위치)이 동시에 학습되서 SGD가 가능하다는 것입니다.
Conclusion
기존 NMT는 Seq2Seq 모델로 고정적 vector만 써야 해서 긴 문장에 대한 처리가 어려웠지만 본 논문에서 제안한 RNN-search는 Attnetion 개념이 들어가서 가변적인 vector를 사용하더라도 예측하려는 단어 주변, 혹은 가장 관련이 있는 단어의 vector 값을 사용하기 때문에 (Attention 개념) 긴 문장이 들어오더라도 상대적으로 더 높은 성능을 보일 수 있었다.



댓글