음.. 본 논문을 리뷰한 글이 보이지 않네요... 왜일까요...
혹시 제가 처음...? 뭔가 살짝 쌔하긴한데... 한번 읽어보도록 하겠습니다!
본 논문에 들어가기 앞서 제목 먼저 분해해보겠습니다.
지난 논문 리뷰와 완전 흡사합니다. 실제 LiDAR를 사용하지 않고도 LiDAR와 유사한 depth information을 생성해서 3D 객체를 감지하는 방법에 대해서 이야기합니다.
end-to-end : 입력에서 출력까지의 과정이 명확하게 구조화되어 있다는 것을 의미합니다. 이 모델은 복잡한 전처리 단계 없이 원시 입력 데이터(이 경우 이미지)를 받아들이고, 원하는 결과(이 경우 3D 객체 감지)를 직접 출력합니다
읽고 난 후
해당 논문은 3D depth map 과 3D object detection을 연결시켜 backpropa를 진행해 loss를 줄이는 부분이 이전 논문과의 차이점이라고 할 수 있을 거 같아요. depth map의 loss를 개선하는 방향으로 진행했다고 할 수 있을 거 같아요. 실제로 실험을 통해 SOTA를 갱신한 걸 보면 일리가 있다는 생각도 드네요. 다만 아쉬운 점이 있다면 학습 이미지 데이터가 해상도가 낮고 충분하지 못한 label 값으로 성능의 한계가 보인다는 점이예요. 데이터의 중요성을 다시 한번 느끼면서 이제 해당 논문을 구현한 코드를 가져와서 이런 저런 실험을 해봐야 할 거 같아요!
다음 편은 코드 리뷰와 논문 실험 재현으로 진행될 거 같아요!
감사합니다!
Abstract
LiDAR는 정확하지만 겁나게 비싸다. 지금까지 Psedo-LiDAR(이하 PL)은 2D depth map을 3D poin cloud로 변환하고 이를 통해 3D detection을 진행했고 이 두 단계를 따로 따로 학습시켰다면 본 논문을 이러한 방법을 End-to-End로 학습시키는 새로운 framework를 제안합니다. 이 framework는 3D point cloud를 사용해 3D object detection을 진행하는 PointRCNN을 같이 사용해서 현재(본 논문을 작성하던 시기) KITTI에서 leaderboard를 달리고 있습니다.
라고 하네요.
뭔가 저번 논문을 좀 더 업그레이드 한 것 같은 느낌이 팍팍 듭니다.
Introduction
여기서 깜짝 놀란 부분이 있습니다. 당연히 여기선 self-driving car 에서 3D object detection의 중요성을 언급하고 있습니다. 그리고 현재 LiDAR를 input 값으로 하고 있는데 64-beam model이 차 한대 가격보다 더 비쌀 수도 있다고 하네요ㄷㄷ..
저는 비싸봐야 얼마나 비싸다고 pseudo-LiDAR를 만드나 했는데 장난 없네요...ㅎ
(테슬라가 비싼 이유를 찾았다...!)
이 대안이 바로 comodity(stereo) camera. 예시로 계속 봤던 PL입니다. 암튼 현재 PL은 image-based 3D detection accuracy에서 34.1%, 42.4%를 달리고 있답니다.
네, 논문 형식이 결과 - 문제 - 그래서 내가 제안하는 방법 - 결과 - 추후 방향 이런 형식으로 진행되는 걸 감안해서 읽었을 때 지금 본 논문은 기존 PL의 방식에 대해서 설명하고 문제점을 이야기하고 있습니다.
PL은 보통 2가지 단계로 나뉘는데 (이미지를 3D point cloud로 바꿈, 그거를 3D detection algorithm에 넣음) 이를 따로 따로 진행하는 건 detection accuracy를 극대화하는 목표에 최적적으로 정렬? 그러니까 이렇게 하는게 3D detection을 하는데 도움을 줄 거 같지 않다고 하네요.
예를 들어서 depth estimators는 loss를 낮추기 위해 모든 pixels에 있는 값들을 수정하려고 할 겁니다. 결과적으로 이 값들은 극과 극의 값을 가지게 될거예요. 그니까 관계가 없는 pixel들이 높은 값을 가지게 될 수도 있다고 합니다. 그리고 이전에 언급했던 PL에서 먼 거리에 있는 물체를 가까운 물체로 인식하는 문제점이 악화될 수도 있다고 합니다.
그래서 새로운 3D object detection을 제안한다고 하네요.
그리고 이제 해당 방법에 대해서 설명을 해줍니다. 그리고 제안된 방법이 굉장한 성능 향상 또한 보였다고 자랑합니다.
이게 이름이 E2E-PL with PoiontRCNN 이라고 합니다. 아.. PointRCNN이 뭔지 찾아봐야겠네여ㅎㅎ...
Related Work

3D object Detection : 2가지 흐름이 있다.
Pseudo-LiDAR : 이미지에서 Z(u,v)라는 depth를 추가한다. 그리고 이를 LiDAR에서 사용하는 알고리즘에 넣는데 이를 구하는 따로 따로 구하는 알고리즘이 KITTI benchmark에 최고점을 찍었는데 본인들의 방법이 이 framework보다 위를 찍었다고 합니다.
End-to-End Pseudo-LiDAR
자, 드디어 대체 그게 뭔지 한번 알아볼까요?
PL의 주요 이점은 plug-play 모듈성으로 3D 깊이 추정 또는 LiDAR 기반 3D detection의 발전을 통합할 수 있는 것이라고 합니다. 하지만 이게 궁극적으로 detection accuracy를 최대화 시키는 부분에는 부족한 부분이 있다고 합니다.

요게 본 논문에서 제안한 PL의 구조이고 저기서 Detction Error를 통해서 depth에서 중요한 부분을 수정할 수 있게 한다고 해요! 이런 걸 soft attend라고 하는 거 같아요. 이를 위해선 측정된 depth에 대해서 depth estimator와 object detector가 미분 가능해야한다고 합니다. 거기에 중요한 2개의 타입이 있는데 subsampling이랑 quantization이라고 하네요!
Quantization
몇몇 LiDAR를 기반으로한 object detector는 2D를 3D 나 4D로 확장시키는 tensor를 input 값으로 갖습니다. 이 3D point locations는 고정된 격자표로 이산화되는데 여기에는 점유나 밀도만 기록됩니다. 이 방식의 장점은 2D 또는 3D convolution을 이용해서 텐서에서 직접적으로 특징을 추출할 수 있는 점이라고 합니다. 하지만 이런 이산화과정은 역전파를 어렵게 만든다고 합니다.
네, 순전파는 직관적인데 역전파는 어렵다. 그거를 구체적으로 한번 볼까요?
Bin: 'Bin'은 종종 데이터를 구성하고 정리하는 데 사용되는 '버킷' 또는 '상자'로 생각할 수 있습니다. 예를 들어, 연령대별로 사람들을 그룹화하려면, "20대", "30대", "40대" 등과 같은 연령대 'bin'을 만들 수 있습니다. 각 'bin'은 그 안에 해당 범위의 데이터를 포함합니다.
A bin is a small area or region in a larger space, and in this context, it likely refers to a specific area in a 3D point cloud.
이산화 (Discretization): 이산화는 연속적인 값을 이산적인 값으로 변환하는 과정입니다. 예를 들어, 온도 데이터가 연속적인 실수 값으로 주어진 경우, 이를 '냉각', '온난', '고온' 등의 이산적인 카테고리로 변환할 수 있습니다. 이산화는 머신 러닝 모델에서 다루기 쉬운 형태로 데이터를 변환하는데 유용하며, 특히 범주형 데이터를 처리하는 데 사용됩니다.
이산이란 연속성이 전혀 없는 분리된 상태를 말한다.
bin 이라는 객체의 특징을 표현하는 공간이 있습니다. 그리고 우리의 목표는 point clout P가 그 bin의 tensor를 표현하는 T를 만들어내게 하는 게 목표입니다. 아무튼 순방향은 그냥 직관적으로 하면 되지만 loss 를 T(m)으로 미분 했을 때 직관적으로 음수이면 T(m)이 증가하고, 양수이면 T(m)이 감소하게 하면 됩니다. 그런데 어떻게 이 값을 point cloud P가 각각의 bin이라는 공간에 사용될 수 있도록 전달할 수 있을까요?
결국
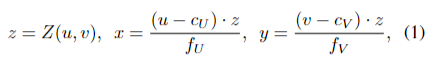
이 식에서 backward pass는 non-trivial이고 역전파를 적용하기 어렵다는 것입니다 (T(M) -> cloud P까지)
그래서 어떤 걸 제안하냐면 forward pass를 미분 가능한 soft quantization module을 사용하도록 수정하는 겁니다.

Figure4를 읽어 볼게요. PL로 point cloud를 만들고 Quantization을 해줍니다.여기서 초록색 voxels는 PL point의 영향을 받습니다. 파란색 voxel은 loss를 본인의 voxel에서 멀리 떨어지도록 하고 빨간색 voxel은 본인에게 더 가깝게 당긴다고 하네여. 이런 voxels가 PL point에 영향을 준다고 해요. Soft quantization은 Hard보다 더 많은 vexel들을 가지고 있으며 이를 통해서 PL이 실제 LiDAR point cloud에 가까워질 수 있다고 합니다.
Radial Basis Function (RBF)은 실수 공간에 정의된 실수 값을 반환하는 함수입니다. 이 함수의 값은 원점에서의 거리에만 의존하는데, 이런 특징 때문에 'radial'이라는 이름이 붙었습니다.
The RBF is a type of function that takes a distance as input and outputs a value based on that distance.
RBF를 사용함으르써 bin 내의 점들에 가중치를 부여 => bin 내의 객체들의 특성을 더 정확하게 측정할 수 있고 하네요. 이 RBF를 이용해서 Figure4를 유도하는 거 같아요.
밤이라서 그런지 모르겠는데
"m"과 "m'"가 가리키는 두 데이터 영역(bin)을 좀 더 살펴보겠습니다. 이 두 bin은 각각 다른 범위의 데이터를 포함하고 있을 수 있습니다.
RBF 가중치는 데이터 포인트들 사이의 유사도를 측정하는데 사용됩니다. 이 경우, "bin m'에 대한 bin m의 평균 RBF 가중치"라는 표현은 bin m 내부의 각 데이터 포인트에 대해 bin m' 내부의 데이터 포인트들과의 RBF 가중치를 계산하고, 이를 평균내어 bin m'의 평균 RBF 가중치를 구한다는 것을 의미합니다.
이게 이해가 잘 안갔습니다. 이제는 이해가 갑니다. m 과 m'라는 공간bin이 존재합니다. 두 공간에 있는 point의 유사도를 RBF가중치로 측정합니다. 그래서 그 결과를 bin m'의 평균 RBF 가중치를 구한다고 이야기합니다. 그리고 이걸 T(m,m') 라고 표기합니다.
라고 하네요 ㅠㅠ
그래서 최종 tensor T의 값은 주변의 bins와 이것 자체의 sofrt occupation의 합이다. 라고 말합니다.
아무튼 quantization 을 위해서 설정한 하이퍼파라미터에 대해서 설명합니다. 그래서 이렇게 구한 미분 값은 끝과 끝 학습에 전파될 수 있다고 합니다. 이때 chain rule을 사용해서 m' bin에 있는 point를 부분적으로 미분한 값을 전달할 수 있습니다. 그리고 bin이 실수로 점을 포함하지 않는 경우에도 주변의 점을 들래그 할 수 있게 해서 깊이 오류를 효과적으로 수정할 수 있게 한다고 하네요!
Subsampling
Voxelization의 대안점으로 LiDAR-based object detectors는 3D point를 입력값으로 받는데 Equation 1으로 얻은 3D point cloud를 사용하기 위해 subsampling이라는 과정이 필요하고 이 과정이 end-to-end 방식에 더 적합하다고 합니다.
그리고 그 방법에 대해서 설명합니다.
첫째로 LiDAR신호가 cover할 수 있는 highest signals보다 높은 값을 모두 제거했다고 합니다.
그리고 subsampling으로 남은 점들을 희소화시킬 수 있는데 이런 방법은 실제 LiDAR 신호가 18,000개인데 PL에는 300,000개의 점들이 있는 depth map 때문에 선택적이지만 권장된다고 합니다. 물론 이런 점들이 정확성에는 도움을 줄 수 있지만 속도를 크게 낮추기 때문에 권장된다고 하네요.
제가 이해한 바로는 저렇게 나온 point들을 이산화 시켜서 3D 다중 빈을 정의한다고 합니다.
We define mul-tiple bins in 3D by discretizing the spherical coordinates(r, θ, φ)
이런 과정이 3D space를 묘사할 수 있게 하고 obeject detection같은 걸 위해서 사용된다고 하네요. 그래서 본 논문은 polar angle과 azimuthal angle을 LiDAR beam을 모방하게 하기 위해서 이산화시킨다고 합니다. 그런 다음 3D Point를 그 bin에 머물 수 있도록 유지시키면 결과적인 그 point cloud가 실제 LiDAR point를 모방할 수 있게 되는 거라네요!
정리를 해보자면 subsampling을 통해 희소성을 띄는 점들을 유지 시킵니다. 그리고 해당 점들을 이산화시켜서 3D bin 영역에 둡니다. 더 구체적으로 해당 가중치들을 LiDAR beams에 맞도록 이산화시킴으로써 기존에 존재하던 3D points 값을 그것과 같은 bin에 둠으로써 point cloud가 실제 LiDAR point에 맞도록 유도하는 거 같아요!
그래서 역전파 관점에서 보면 3D object detector가 직접적으로 3D 좌표를 처리하기 때문에 3D 좌표에 대한 최종 detection loss를 얻을 수 있고 feed forwad를 적절하게 진행했다면 object detection 부터 depth estimate Z까지 직관적으로 역전파가 될 수 있다고 합니다.
근데 어떤 이유 때문에 초기 깊이 손실이 필요하다고 하는데 이건 무슨 말인지 모르겠어요 ㅠ
근데 이 detail이 end-to-end traing을 성공적으로 수행하는 데 꼭 필요하다고 하네요
Loss
심호흡 한번 하고 들어갈게요... 후...
이제 loss를 통해 object detector 와 depth estimator를 배운다고 합니다.

object detector 와 depth estimator의 loss 변수를 설명하고 있어요.
이때 Ldet 는 물체를 적절하게 bounding 했는지 분류를 해주는 classification loss와 해당 box가 적절한 크기로, center가 잘 맞았는지, 각도가 맞았는지 에 대한 regression loss의 합이라고 하네요.
그리고 Z를 예측한 depth라고 하고 Z*를 실제 값이라고 했을 때 Ldepth를
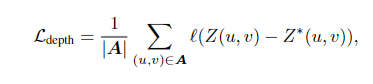
라고 정의할 수 있겠죠. 이때 |A|는 실제 depth를 가지는 pixels의 집합입니다. 그리고 l은 L1 loss로
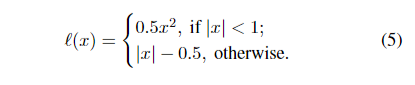
위와 같이 정의했다고 해요.
그래서 물체 감지로 인한 손실이 픽셀의 일부에만 영향을 미칠 수 있기 때문에 깊이 손실이 중요하다는 걸 발견했다고 해요. 그래서 뭐를 바라나면 이 깊이 측정-먼 거리에 있는 물체 주변의-이 더 정확해지면서 주변의 물체와 배경에서 깊이의 정확도를 손실하지 않기를 바란다고 하네요
Experiments
위 가정을 실험한 결과를 보여주네요. 모델 명은 E2E-PL이며 KITTI object detection betchmark로 정확도를 평가했다. label로는 KITTI에서 제공하는 64-beam Velodyne LiDAR point cloud에 상응하는 이미지를 사용했다고 합니다. 그리고 어떤 함수, 모델을 썼는지 알려줍니다.
Detail을 알려주시는데 Depth estimation를 먼저 하고 해당 depth network를 고친 다음 이것의 output으로 3D object detection을 학습시킨다고 합니다. 그리고 두 부분을 균등한 loss weights로 같이 학습시킨다고 합니다.
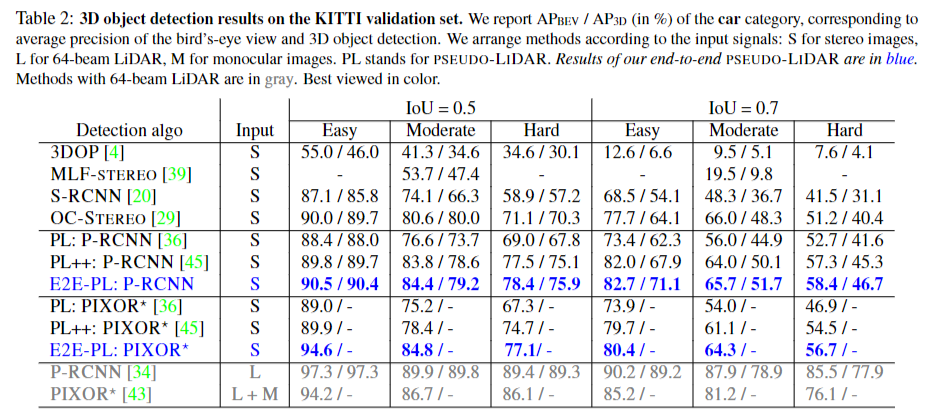
해당 테이블로 설명을 대신해보도록 하겠습니다. '차' 종을 분류하는 부분에서 정확도를 나타냅니다. blue가 본 논문에서 제안한 detection algorithmn이라고 보면 될 거 같습니다.S는 stereo image 타입으로 이미지를 뜻하겠지요. 보시는 것처럼 IoU = 0.5 - Easy에는 굉장히 큰 AP/AP를 보이지만 Hard에서는 상대적으로 gray보다 낮은 AP/AP를 보이는 걸 알 수 있습니다.
Ablation studies
딥 러닝 모델에서 특정 레이어나 알고리즘이 결과에 어떤 영향을 미치는지 알아보기 위해 해당 레이어나 알고리즘을 제거하고 성능을 비교 하는 방법입니다.

이건 수치의 값이고 사진으로 결과를 보여주기도 합니다.


E2E-PL BEV로 봤을 때 생각보다 잘 예측된 걸 확인할 수 있습니다.
Conclusion and Discussion
E2E-PL은 SOTA를 갱신했습니다. 그렇지만 여전히 LiDAR를 추가하는 것이 더 유익하지만 그런 센서의 비용을 정당화하기엔 그 이익이 너무 작아질 수 있다고 합니다. 그러니까 본인들의 E2E-PL을 쓰면 싼 가격에 유사한 성능을 낼 수 있다! 라고 주장하는 게 아닌가 싶어요. 마지막으로 KITTI 의 이미지 데이터가 상대적으로 해상도가 낮고 라벨링된 멀리 떨어진 객체들이 드물다는 점을 지적하면서 멀리떨어진 객체들에 대한 라벨이 더 있다면, 그리고 해상도가 더 높다면 hard category에서 성능 개선이 있을 거라고 하네요!
이렇게 해당 논문은 끝이 납니다.



댓글