*논문 내용 뿐 아니라 필자의 주관적인 내용 + 다양한 출처의 내용이 들어가 있는 리뷰입니다.
Abstract
GPT generative pretrained transformer family 모델에 최소 50% 이상을 sparse하게 가지치기했다고 한다.
재학습이 없고 sparseGPT라는 새로운 pruning method를 사용했다고 한다.
이 메서드를 오픈 소스 모델에 적용을 시켰고 perplexity 에서 무시할 ㅅ구 없는 성능 향상을 보였다고 한다.
1. Introduction
LLMs 이 GPT 방법으로 가면서 굉장한 연산 비용을 요구하게 되었다.
그래서 compression이 대두 되었고 그 중 하나가 Pruning 방법이다.
Pruning에는 Unstructured Pruning 과 Structureed Pruning 방법이 있는데 전자의 경우 개별 가중치를 임의로 삭제하는 방법이다.
후자는 더 높은 수준의 구조, 예를 들어 가중치 매트릭스의 행이나 열을 제거하는 방법이다.
그래서 비구조적 pruning 은 모델의 크기를 줄이는데 효과적이지만, 일반적인 하드웨어에서 실행할 때 성능 향상이 덜 뚜렷할 수 있고 구조적 pruning은 신경망의 아키텍처를 보다 명확하게 변경하며, 일반적으로 하드웨어의 실행 효율성을 더 크게 향상시키는 특징을 가지고 있다.
기존 Pruning 은 retraining이 필요하기 때문에 GPT scale 모델에서 굉장히 비싸다는 단점을 가지고 있다. 그래서 현재까지 수십억개의 파라미터를 가진 모델의 정확한 pruning 방법은 없다고 할 수 있다.
이 논문에서 우리는 SparseGPT를 제안한다. 이 방법은 10 ~ 100+ 억개의 파라미터의 모델에서 효율적으로 정확한 one-shot pruning을 할 수 있는 방법이다.
Overview - SparseGPT에 대한 개략적인 설명. 아직 잘 모르겠지만 sparse regression의 instances를 새로운 sparse로 바꿈으로써 진행하는 게 아닌가 싶다.
또 실험 결과에서 1. 제안된 방법은 60%의 sparsity를 가져가면서 최소한의 정확도 감소를 가져갔고 기존 pruning은 동일한 정확도를 위해 10% sparsity를 가져갔다는것을 보여준다.
2.

두번째로 Sparsity의 비율에 따라서 Perplexity가 달라지는 걸 확인할 수 있었고 이를 통해 더 큰 모델일수록 더 경량화가 잘될 것이라는 인사이트를 얻을 수 있었다.
또 하나 SparseGPT에서 확인해야 할 속성으로 각 layer의 입출력 관계를 유지하기 위해 설계된 가중치 업데이트에만 의존한다는 것이다. 즉 각 layer의 가중치를 업데이트할 때, 그 계층이 처리하는 정보에만 집중한다. 그러니까 입력 데이터를 받아 출력을 생성하고, 가중치 조장은 오직 그 layer의 데이터 처리 효율성을 최적화 하는데 중점을 둔다. 이걸 지역적 가중치 업데이트라고 한다.
As such, we find it remarkable that one can directly identify such sparse models in the “neighborhood” of dense pretrained models, whose output correlates extremely closely with that of the dense model.
이 문구가 잘 이해가 안갔다. 희소 모델이 밀집 사전 훈련 모델의 '근처'에서 직접 식별될 수 있다는 점을 놀라운 점으로 지적한다. 여기서 '근처'란 모델의 매개변수 공간 내에서의 위치를 의미한다.
이게 무슨 뜻일까?
먼저 희소 모델이란 많은 가중치가 0이거나 비활성화되어 있어 더 적은 수의 가중치만을 사용하는 신경망을 의미한다.
매개변수는 보통 벡터 값을 가지고 있으며 공간적인 의미에서 어느 공간에 이 값들이 존재한다고 생각할 수 있다. 그래서 사전 훈련된 밀집 모델의 매개변수 공간 내에서, 얘들이 출력하는 값과 매우 유사한 출력값을 가지는 희소 모델을 직접 찾을 수 있다는 것 이다.
그러니까 사전 훈련된 밀집 모델의 매개변수를 약간만 조정함으로써, 효율적인 희소 모델을 생성할 수 있고 이 희소 모델이 사전 훈련된 밀집 모델과 유사한 출력 값을 가진다는 것을 의미한다.
어떻게 이를 구현하는 지는 추후에 배워보도록 하자.
2. Background
Post-Training Pruning
*모델이 학습을 완료한 후에 불필요하거나 중요하지 않은 가중치를 제거하는 과정
Layer-Wise Pruning
*특정 계층의 가중치를 제거하는 최적화 기법 / 계층별 중요도 평가 > 중요도가 낮게 평가된 계층의 가중치 제거 > 성능과 정확도 유지하도록 재학습으로 진행된다.
Post-Training Compression은 full-model compression문제를 layer-wise subproblem으로 나눔으로써 진행되는데 얘는 압축된 모델과 되지 않은 모델의 output 값의 loss를 통해서 solution quality가 측정된다.

이런 식으로 되며 Wl은 압축되지 않은 가중치이고 Ml * W^l은 sparsity mask와 업데이트된 가중치 그러니까 압축된 layer의 가중치라고 생각하면 되겠다. 그래서 이를 빼고 제곱해서 loss값을 구할 수 있고 The overall compressed model is then obtained by “stitching together” the individually compressed layers , 이렇게 구해진 layer들을 통합함으로써 전체 압축된 모델을 만들 수 있다.
Mask Selection & Weight Reconstruction
(1)의 핵심은 Ml과 W^l이 같이 최적화된다는 것이다. 그리고 이게 NP-hard라는 문제를 발생시킨다. 왜냐면 최적의 희소 확장을 찾는 것이 일반적으로 NP-hard 문제로 알려저 있기 때문이다.
*NP-hard : 이론적으로 해결하기 매우 어려운 문제
그래서 이를 정확하게 해결하는 건 비현실적이며 해결하기 위해 최대한 근사한 값에 수렴하도록 한다.
가장 유명한 접근 방법은 이 문제를 mask selection 과 weight reconstruction으로 분리하는 것이다.
구체적으로 어떤 기준에 따라서 pruning mask M을 정하고 mask가 변하지 않도록 최적화한 뒤 남은 unpruned weights를 최적화하는 방법이다.
Existing Solvers.
현재까지 이 문제를 해결한 방법 중에 가장 좋은 결과를 보인 AdaPrune approach가 있다. 그러나 이 approach도 큰 파라미터를 가진 모델에서 이상적인 speed/accuracy 가 반비례하는 걸 볼 수 있다. 1.3B를 최적화 할 때 몇 시간이 걸리고 175B 를 최적화 할 때는 몇 백시간이 걸린다.
더 정확한 approaches는 최소한의 시간이 필요하고 AdaPrune보다 비싸고 linear scaling 보다 성능이 낮다. 이게 뭘 의미하냐면 정확한 post-training 기술을 거대한 모델에 적용하는 게 도전적인 노력이라는 것이다. 그래서 SparseGPT를 제안한다, 이게 신중한 근사를 기반으로 거대한 모델을 runtimes와 정확도를 쉽게 scale할 수 있도록 해주는,
3. The SparseGPT Algorithm
3.1 Fast Approximate Reconstruction
후.. 올게 왔다.
먼저 Hessian Matric가 뭔지에 대해서 알아보자.
Hessian Matric : 다변수 함수의 2차 미분으로 구성된 정사각형 행렬. 이 행렬은 함수의 국소적인 곡률을 나타내며, 최적화 문제에서 중요한 역할을 한다.

그래서 Hessian Matric로 국소 최소값, 최대값, 안장점을 결정할 수 있고 이를 통해 목적 함수의 최소화 또는 최대화 지점을 찾는 데 중요한 도구가 된다.
이제 어떻게 sparse reconstruction problem을 해결하는 지 보자. (각 matric row w^i를 어떻게 spare reconstruction 할까?)
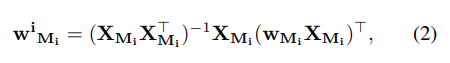
XMi는 row i에서 pruned 되지 않은 weight이다.
wMi는 respective weight이다. 그러니까 wMi가 pruning 후에도 남아 있는, 모델의 성능에 여전히 중요한 역할을 하는 가중치라는 것을 의미한다.
Hessian matrix HMi = XMiX> Mi 얘를 역행렬로 변환하는 것이 필요하다고 한다.
시간 복잡도에 대해서 설명하는데 (n x n 의 행렬을 역행렬로 변환하기 위해선 대략 O(n^3) 의 시간이 필요하다고 한다) 각 열이 dcol 차원을 가진다고 할 때 O(dcol^3) 의 복잡도가 걸리고 drow 의 행의 수를 가진다면 O(drow*dcol^3)의 시간이 필요하다고 말한다. 그래서 Transformer 모델의 경우 전체 실행 시간이 숨겨진 차원 d hidden의 4제곱에 비례하기 때문에 d hidden에 따라 복잡도가 매우 빠르게 올라가므로 실용적인 알고리즘을 얻기 위해서는 최소한 hidden dimension 의 전체 요소에 의한 속도 향상이 필요하다고 합니다. ( 예를 들어, 이 1000이라면, 알고리즘의 속도를 최소한 1000배 빠르게 만들어야 실용적이라는 것입니다 )
Different Row-Hessian Challenge.
Pruning 후 남은 가중치를 최적으로 복구하는 데 계산 복잡도가 높은 이유 중 하나는 각 행(row)마다 크기의 행렬의 역행렬을 개별적으로 계산해야 하기 때문입니다. 이는 각 행마다 다른 Pruning 마스크 를 가지고 있기 때문이며, 마스크된 Hessian의 역행렬이 전체 Hessian의 역행렬의 마스크 버전과 같지 않다는 사실에 기인합니다.

각 행이 mask를 공유하도록 하는 건 역행렬을 계산하는 필요성을 없애 줄 수 있지만 초종 모델의 정확도에 중대한 영향을 끼칠 수 있는 문제가 있고 전체 열과 같은 큰 구조에서 가중치를 희소화하는 것은 개별적으로 pruning하는 것보다 더 어렵다.
그래서 저자들은 서로 다른 pruning 마스크를 가진 행들 사이에서 hessian을 재사용 할 수 있는 알고리즘을 제안하며 이 알고리즘은 정확도와 효율성을 모두 달성하기 위해 설계되었다.



댓글