읽고 난후
그렇다면 verify를 한 각 step에 대한 edit을 하면 성능향상이 되지 않을까?
들어가기 전
Review를 통해 이해한 걸 바탕으로 먼저 이야기를 하면 수학 문제를 LLM이 풀 때 Reasoning Path를 생성하면서 최종 output을 생성함, 근데 이 Reasoning Path를 Solution이라고 하며 각 Solution에서 여러가지 Reasoning Path가 진행이 됨 여기서 각각의 Reasoning Path가 옳은지 PRM이라는 Classifier를 통해서 판단을 함.
그렇다면 해당 논문에서 제안하는 건 어떤 Solution에 대한 개선보다는 더 좋은 Solution을 선택하는 Classifier를 제안하는 건가? 하는 생각이 들었음
그래서 사실 아직 논문을 읽기 전에 던졌던 2가지 질문
- How to improve the performance of the model(Generator which is making solutions)?
- How to verify the reasoning path sucessfully?
에 대해서 2번 질문에 대해서 답을 할 수 있고 1번은 해당 사항이 없는 게 아닌가 하는 생각이 들었다.
그래서 리뷰를 좀 더 읽어보고 그리고 논문을 좀 더 읽어보면서 생각을 해봐야 할듯 함.
Abstract
리뷰에서 이야기한 것과 동일함. 과정에 대한 supervision을 통해서 최종 output에 대해서만 학습을 하는 것보다 더 나은 결과를 낼 수 있도록 했고 데이터셋도 공개를 한다고 함. 그리고 active learning이 뭔지는 모르겠는데 이를 통해서 과정 supervision의 효과를 상당히 많이 향상 시켰다고 함
Introduction & 본 논문의 Motivation
모델이 똑똑하긴 한데… 잘 모르면 hallucination을 생성해버림 → 수학을 푸는 Task 같이 Multi-step reasoning이 필요한 Task에는 굉장히 심각한 문제라고 할 수 있음 이러한 문제를 완화시키는 방법 중 Reward models에 집중함
심플하게 이야기하면 이 RM은 hallucination이 발생하지 않은 output을 선택할 수 있게 도와줌
본 논문에서 사용한 방법은 ORMs (Outcome-supervised reward models)와 PRMs(process-supervised reward models) 임
ORM은 최종 output을 사용하는 거고 PRM은 중간 과정 즉, reasoning path를 사용해서 결과를 내게 하는 거임. 기존에 Uesato et al. (2022)가 이걸 먼저 실험했는데 ORMs + PRMs 둘 다 사용한 거랑 ORMs 하나만 사용한 거랑 별 차이가 없다고 주장했음
근데 OpenAI에서 우리가 해봄 ㅋ 해서 몇 개 바꿔서 해봤더니 너무 좋던데? 하고 contribution을 때려버림..
Method
여기서 질문 1에 대한 답이 나옴 → We do not attempt to improve the generator with reinforcement learning. 이라고함
RM에 넣어지는 output이나 process에 대해서만 이야기할 거임.
그리고 RM의 평가는 Generator 가 생성한 solutions 중에 best-of-N search로 평가를 할 거임.

데이터셋 구성 → Generator가 저렇게 생성할 수 있도록 fine-tuning했음
그래서 사람이 긍정, 부정, natural(애매함을 처리하기 위함) labeling을 할 수 있게 했음
이렇게 구성한 데이터셋이 PRM800K로 12K의 문제들, 75K의 solutions 그리고 800K의 과정에 대한 human label로 이뤄져있음.
그리고 오버피팅을 최소화하기 위해서 4.5K MATH test problems를 학습 데이터에 넣었
전략적 솔루션 선택 : 명백하게 틀린 답을 제시하면 당연히 RM은 잘 판단할 거임. 근데 뭔가 설득력있는 정답 같은 솔루션인데 최종 답이 틀린 솔루션이 있어. 그러면 RM은 처음에는 높은 자신감으로 정답을 찍었다가 틀리니까 이에 대해서 더 많은 정보를 얻을 수 있을 것이다. 라고 주장함
각 iteration 마다 problem1개에 N 개의 solution을 바탕으로 top-K 개의 convincing worng-answer 데이터를 골랐다. (data collection process가 매우 비싸 process에 대한 ablation 과정을 진행할 수 없다고 말함.)
ORMs - Outcome-supervised Reward Models
최종 output이랑 target을 비교 → true or false를 비교함
PRMs - Process-supervised Reward Models
step-level에서 정답인지 아닌지를 판단함 이때 PRM score을 사용하는데 이거롤 각 solution들이 정답인지 아닌지를 판단하는 평가 점수로 삼는다.
또 학습전략으로 첫번째 단계에서 오답을 supervision으로 넣는데 이렇게 하면 마지막 단계까지 가지 않더라도 해당 solution이 오답이라고 할 수 있어서 인간 레이블러에게 비슷한 작업 부담을 줄 수 있게 함 / 이때 추가적인 process supervision을 줌으로써 더 많은 피드백을 얻을 수 있게 한다고 함.
Large-scale Supervision
PRM과 ORM을 학습 시킨 데이터셋이 다르다. PRM800K로 ORM을 학습을 시켰는데 이게 좋지 않았음. 따라서 PRM과 ORM의 동등한 비교는 어려움
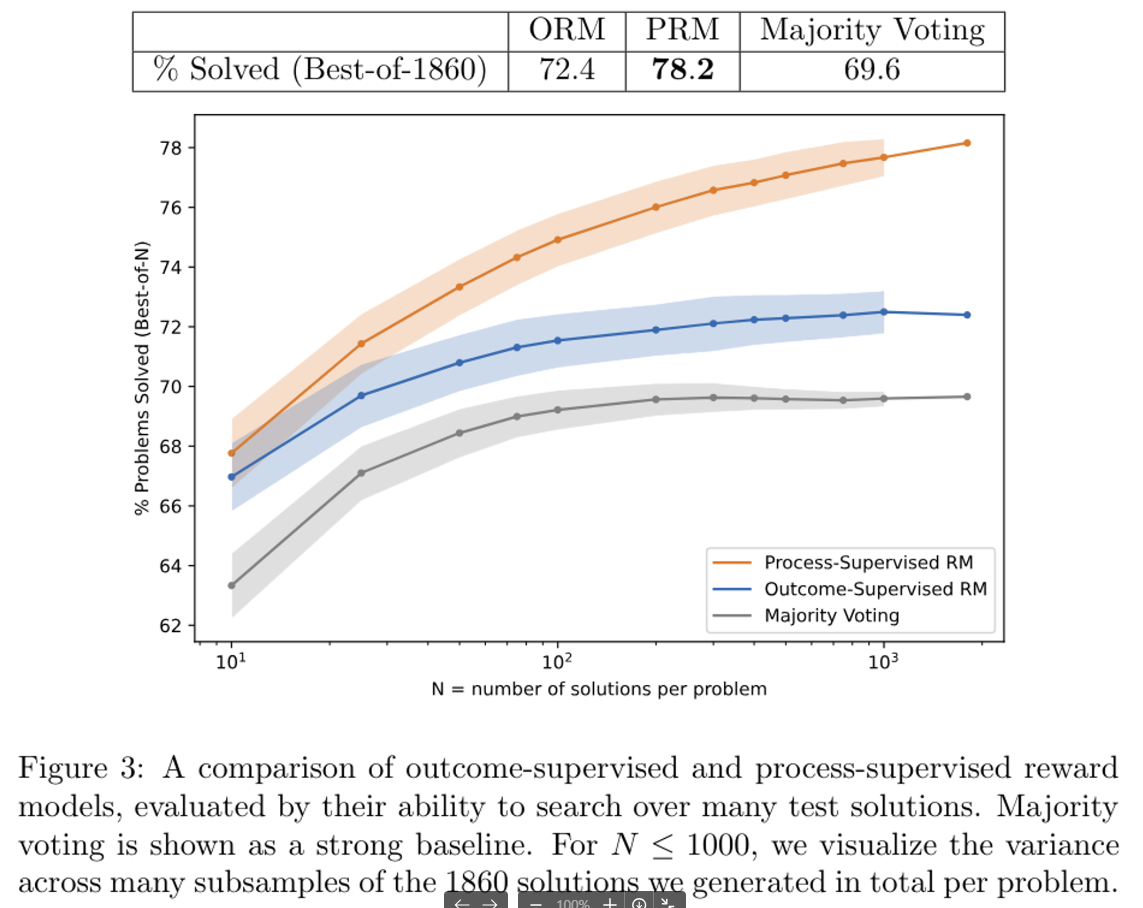
내 해석은 이렇다. 문제에 대한 solutions가 많을 수록 OPM, PRM은 본 모델들의 필요한 classify를 잘 한다. 그리고 a strong baseline이 의미하는 건 Wang et al. 2022에서 제안된 모델이다.
의문점
그러면 ORM과 PRM을 같이 쓰는게 아니라 둘 중 하나만 쓰는 건가?
-> 그렇다.
Process vs Outcome Supervision
PRM이 제일 성능이 좋음 → 왜일까? 추측을 해보면 PRM은 잘못된 reasoning이 오더라도 올바른 final answer로 도달할 수 있게 하는 solutions에 대한 더 나은 supervision을 제공하기 때문이라고 주장함
내 생각엔 PRM이 결국 여러가지 solutions 중에 best를 뽑는 거잖아? 그러니까 incorrect reasoning 이 오더라도 final answer는 정답이 오게끔 해주니까 결국 PRM으로 선택된 best-of-N solutions는 결국 correct한 answer로 도달 할 수 있게끔 해주니까 ORM, final answer something보다 성능이 더 높게 나오는 거라고 이해했음
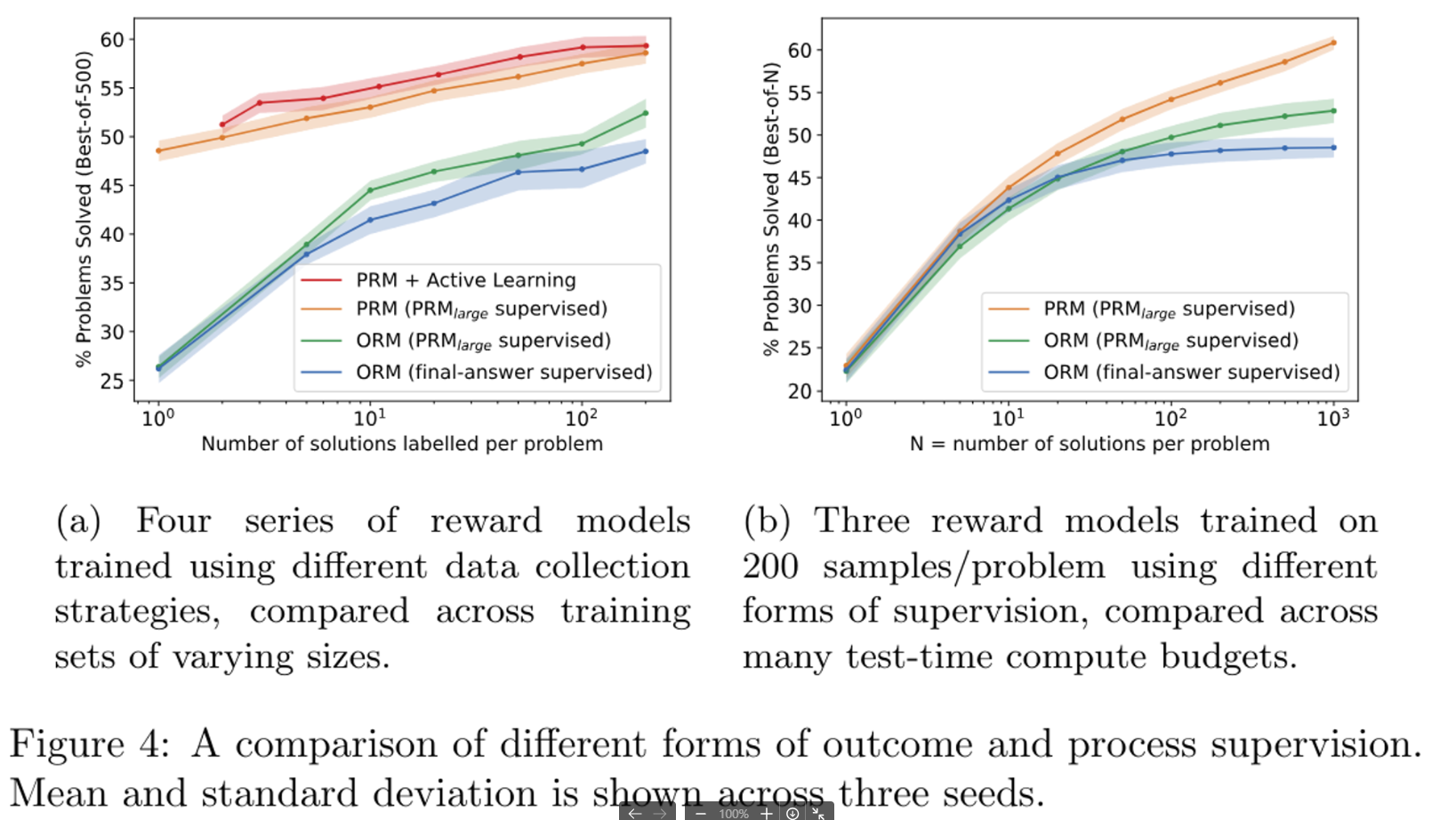
이제 여기 의미하는 dataset form of supervision임 어떤 형태인지는 모르겠지만 label에 대한 dataset이라고 이해하고 있음
For each dataset, we provide three forms of supervision: process supervision from PRMlarge, outcome supervision from PRMlarge, and outcome supervision from final-answer checking.
위 글을 이해하면 이해할 수 있음
Active Learning
내가 이해하기론 Active Learning이란 주어진 데이터를 그냥 학습하는 수동 학습이 아닌 주어진 데이터에서 의도에 따라서 필요한 데이터를 학습 할 수 있도록 하는 방법을 의미한다고 생각한다.
이 부분은 능동 학습(active learning)을 통해 보상 모델을 훈련하는 방법과 그 효과에 대해 설명하고 있습니다.
- PRMselector 훈련:
- 작은 규모의 보상 모델인 PRMselector를 각 문제당 하나의 샘플로 훈련합니다. 이 모델은 이후 각 문제당 1000개의 샘플을 평가하는 데 사용됩니다.
- 샘플 선택:
- 더 큰 보상 모델을 훈련하기 위해, 각 문제당 PRMselector에 따라 다음과 같은 비율로 샘플을 선택합니다:
- 80%: 가장 설득력 있는 잘못된 답안 샘플
- 20%: 남은 샘플 중 가장 설득력 있는 샘플 (올바르거나 잘못된 답안 모두 포함)
- 이 선택 과정은 PRMselector에 대해 상대적으로 설득력 있는 샘플들을 선택하고, 많은 샘플이 적어도 하나의 실수를 포함하도록 합니다. 또한, 전체 데이터셋이 잘못된 답안 솔루션으로 너무 편향되지 않도록 합니다.
- 더 큰 보상 모델을 훈련하기 위해, 각 문제당 PRMselector에 따라 다음과 같은 비율로 샘플을 선택합니다:
- PRMlarge로 평가 및 훈련:
- 선택된 샘플들을 PRMlarge로 평가하고 그 점수로 더 큰 보상 모델들을 훈련합니다.
- 데이터 효율성:
- Figure 4a를 통해 능동 학습을 사용한 선형 회귀선의 기울기를 비교함으로써, 능동 학습이 균일한 데이터 레이블링보다 약 2.6배 더 데이터 효율적임을 추정합니다. 즉, 능동 학습을 사용하면 동일한 데이터양으로 더 많은 정보를 얻을 수 있습니다.
- 큰 데이터셋에서의 성능 저하:
- 가장 큰 능동 학습 데이터셋(문제당 200개의 샘플)으로 훈련된 모델이 예상 경향선보다 약간 저조한 성능을 보인다고 언급합니다. 이는 전체 선택 풀(문제당 1000개의 샘플)의 상당 부분을 차지하기 때문에 다양성이 부족해져서 발생할 수 있는 현상입니다.
Discussion
설명
- *Credit Assignment (신용 할당)**은 모델이 솔루션에서 발생한 오류의 원인을 식별하는 과정을 의미합니다.
- 결과 감독의 문제점: 결과 감독으로 훈련된 보상 모델은 솔루션이 틀렸을 때 어떤 단계에서 잘못되었는지를 찾아야 합니다. 이 과정은 특히 어려운 문제에서 매우 어려워집니다. 왜냐하면 대부분의 모델 생성 솔루션에는 어딘가에 오류가 있기 때문에, 부정적 레이블의 정보 가치가 낮아지기 때문입니다.
- 과정 감독의 장점: 반면, 과정 감독은 각 단계별로 피드백을 제공하여, 몇 개의 초기 단계가 올바른지와 잘못된 단계의 정확한 위치를 명확히 합니다. 이렇게 하면 오류의 원인을 정확히 파악할 수 있게 되어 모델의 신용 할당 작업이 훨씬 수월해집니다.
- 결과: 과정 감독이 더 정확한 피드백을 제공함으로써, 보상 모델이 더 잘 일반화할 수 있고, 이는 과정 감독이 결과 감독보다 성능이 뛰어난 이유를 설명합니다.
설명
AI 정렬(AI alignment)
- AI 정렬은 모델이 인간의 의도와 목표에 맞게 행동하도록 하는 것을 의미합니다. AI 모델이 올바르게 정렬되었는지 여부는 그 모델의 안전성과 신뢰성에 중요한 영향을 미칩니다.
과정 감독의 장점
- 해석 가능한 추론: 과정 감독은 모델이 인간이 승인한 과정을 따르도록 유도하여 모델의 추론 과정을 더 해석 가능하게 만듭니다. 이는 모델이 어떻게 결론에 도달했는지를 이해하는 데 도움이 됩니다.
- 본질적인 안전성: 과정 감독은 올바른 사고 과정을 직접적으로 보상하므로, 결과를 대리자로 사용하는 것보다 더 안전합니다. 이는 모델이 인간의 가치와 목표에 맞게 행동하도록 더 잘 유도합니다.
Conclusion
Active learning이 인간 데이터 수집비용을 감소 시킬 수 있음 → 모델이 학습할 데이터 중 가장 정보가 많고 유익한 데이터를 선택하여, 인간 데이터 레이블러가 평가할 데이터 양을 줄임 → 적은 양의 데이터로도 효과적인 학습을 할 수 있게 하여 비용 효율성을 높임.
액티브 러닝은 액티브 러닝으로 solutions들을 선택하고 그 다음에 사람이 labeling을 함.
- PRM800K를 release했음 이거로 reward model 잘 훈련시켜보셈
- process supervision은 아직 연구가 활발히 이뤄지지 않았음, 우리의 노력이 이 method의 일반화를 시키는데 일조, 앞선 길을 밝혔다고 믿음.
들어가기 전
Review를 통해 이해한 걸 바탕으로 먼저 이야기를 하면 수학 문제를 LLM이 풀 때 Reasoning Path를 생성하면서 최종 output을 생성함, 근데 이 Reasoning Path를 Solution이라고 하며 각 Solution에서 여러가지 Reasoning Path가 진행이 됨 여기서 각각의 Reasoning Path가 옳은지 PRM이라는 Classifier를 통해서 판단을 함.그래서 사실 아직 논문을 읽기 전에 던졌던 2가지 질문- How to improve the performance of the model(Generator which is making solutions)?
- How to verify the reasoning path sucessfully?
Abstract
리뷰에서 이야기한 것과 동일함. 과정에 대한 supervision을 통해서 최종 output에 대해서만 학습을 하는 것보다 더 나은 결과를 낼 수 있도록 했고 데이터셋도 공개를 한다고 함. 그리고 active learning이 뭔지는 모르겠는데 이를 통해서 과정 supervision의 효과를 상당히 많이 향상 시켰다고 함모델이 똑똑하긴 한데… 잘 모르면 hallucination을 생성해버림 → 수학을 푸는 Task 같이 Multi-step reasoning이 필요한 Task에는 굉장히 심각한 문제라고 할 수 있음 이러한 문제를 완화시키는 방법 중 Reward models에 집중함본 논문에서 사용한 방법은 ORMs (Outcome-supervised reward models)와 PRMs(process-supervised reward models) 임근데 OpenAI에서 우리가 해봄 ㅋ 해서 몇 개 바꿔서 해봤더니 너무 좋던데? 하고 contribution을 때려버림..여기서 질문 1에 대한 답이 나옴 → We do not attempt to improve the generator with reinforcement learning. 이라고함그리고 RM의 평가는 Generator 가 생성한 solutions 중에 best-of-N search로 평가를 할 거임.데이터셋 구성 → Generator가 저렇게 생성할 수 있도록 fine-tuning했음이렇게 구성한 데이터셋이 PRM800K로 12K의 문제들, 75K의 solutions 그리고 800K의 과정에 대한 human label로 이뤄져있음.전략적 솔루션 선택 : 명백하게 틀린 답을 제시하면 당연히 RM은 잘 판단할 거임. 근데 뭔가 설득력있는 정답 같은 솔루션인데 최종 답이 틀린 솔루션이 있어. 그러면 RM은 처음에는 높은 자신감으로 정답을 찍었다가 틀리니까 이에 대해서 더 많은 정보를 얻을 수 있을 것이다. 라고 주장함ORMs - Outcome-supervised Reward ModelsPRMs - Process-supervised Reward Models또 학습전략으로 첫번째 단계에서 오답을 supervision으로 넣는데 이렇게 하면 마지막 단계까지 가지 않더라도 해당 solution이 오답이라고 할 수 있어서 인간 레이블러에게 비슷한 작업 부담을 줄 수 있게 함 / 이때 추가적인 process supervision을 줌으로써 더 많은 피드백을 얻을 수 있게 한다고 함.PRM과 ORM을 학습 시킨 데이터셋이 다르다. PRM800K로 ORM을 학습을 시켰는데 이게 좋지 않았음. 따라서 PRM과 ORM의 동등한 비교는 어려움내 해석은 이렇다. 문제에 대한 solutions가 많을 수록 OPM, PRM은 본 모델들의 필요한 classify를 잘 한다. 그리고 a strong baseline이 의미하는 건 Wang et al. 2022에서 제안된 모델이다.그러면 ORM과 PRM을 같이 쓰는게 아니라 둘 중 하나만 쓰는 건가?PRM이 제일 성능이 좋음 → 왜일까? 추측을 해보면 PRM은 잘못된 reasoning이 오더라도 올바른 final answer로 도달할 수 있게 하는 solutions에 대한 더 나은 supervision을 제공하기 때문이라고 주장함 위 글을 이해하면 이해할 수 있음내가 이해하기론 Active Learning이란 주어진 데이터를 그냥 학습하는 수동 학습이 아닌 주어진 데이터에서 의도에 따라서 필요한 데이터를 학습 할 수 있도록 하는 방법을 의미한다고 생각한다.
위 글을 이해하면 이해할 수 있음내가 이해하기론 Active Learning이란 주어진 데이터를 그냥 학습하는 수동 학습이 아닌 주어진 데이터에서 의도에 따라서 필요한 데이터를 학습 할 수 있도록 하는 방법을 의미한다고 생각한다.
- PRMselector 훈련:
- 작은 규모의 보상 모델인 PRMselector를 각 문제당 하나의 샘플로 훈련합니다. 이 모델은 이후 각 문제당 1000개의 샘플을 평가하는 데 사용됩니다.
- 샘플 선택:
- 더 큰 보상 모델을 훈련하기 위해, 각 문제당 PRMselector에 따라 다음과 같은 비율로 샘플을 선택합니다:
- 80%: 가장 설득력 있는 잘못된 답안 샘플
- 20%: 남은 샘플 중 가장 설득력 있는 샘플 (올바르거나 잘못된 답안 모두 포함)
- 이 선택 과정은 PRMselector에 대해 상대적으로 설득력 있는 샘플들을 선택하고, 많은 샘플이 적어도 하나의 실수를 포함하도록 합니다. 또한, 전체 데이터셋이 잘못된 답안 솔루션으로 너무 편향되지 않도록 합니다.
- 더 큰 보상 모델을 훈련하기 위해, 각 문제당 PRMselector에 따라 다음과 같은 비율로 샘플을 선택합니다:
- PRMlarge로 평가 및 훈련:
- 선택된 샘플들을 PRMlarge로 평가하고 그 점수로 더 큰 보상 모델들을 훈련합니다.
- 데이터 효율성:
- Figure 4a를 통해 능동 학습을 사용한 선형 회귀선의 기울기를 비교함으로써, 능동 학습이 균일한 데이터 레이블링보다 약 2.6배 더 데이터 효율적임을 추정합니다. 즉, 능동 학습을 사용하면 동일한 데이터양으로 더 많은 정보를 얻을 수 있습니다.
- 큰 데이터셋에서의 성능 저하:
- 가장 큰 능동 학습 데이터셋(문제당 200개의 샘플)으로 훈련된 모델이 예상 경향선보다 약간 저조한 성능을 보인다고 언급합니다. 이는 전체 선택 풀(문제당 1000개의 샘플)의 상당 부분을 차지하기 때문에 다양성이 부족해져서 발생할 수 있는 현상입니다.
Discussion
설명- *Credit Assignment (신용 할당)**은 모델이 솔루션에서 발생한 오류의 원인을 식별하는 과정을 의미합니다.
- 결과 감독의 문제점: 결과 감독으로 훈련된 보상 모델은 솔루션이 틀렸을 때 어떤 단계에서 잘못되었는지를 찾아야 합니다. 이 과정은 특히 어려운 문제에서 매우 어려워집니다. 왜냐하면 대부분의 모델 생성 솔루션에는 어딘가에 오류가 있기 때문에, 부정적 레이블의 정보 가치가 낮아지기 때문입니다.
- 과정 감독의 장점: 반면, 과정 감독은 각 단계별로 피드백을 제공하여, 몇 개의 초기 단계가 올바른지와 잘못된 단계의 정확한 위치를 명확히 합니다. 이렇게 하면 오류의 원인을 정확히 파악할 수 있게 되어 모델의 신용 할당 작업이 훨씬 수월해집니다.
- 결과: 과정 감독이 더 정확한 피드백을 제공함으로써, 보상 모델이 더 잘 일반화할 수 있고, 이는 과정 감독이 결과 감독보다 성능이 뛰어난 이유를 설명합니다.
- AI 정렬은 모델이 인간의 의도와 목표에 맞게 행동하도록 하는 것을 의미합니다. AI 모델이 올바르게 정렬되었는지 여부는 그 모델의 안전성과 신뢰성에 중요한 영향을 미칩니다.
- 해석 가능한 추론: 과정 감독은 모델이 인간이 승인한 과정을 따르도록 유도하여 모델의 추론 과정을 더 해석 가능하게 만듭니다. 이는 모델이 어떻게 결론에 도달했는지를 이해하는 데 도움이 됩니다.
- 본질적인 안전성: 과정 감독은 올바른 사고 과정을 직접적으로 보상하므로, 결과를 대리자로 사용하는 것보다 더 안전합니다. 이는 모델이 인간의 가치와 목표에 맞게 행동하도록 더 잘 유도합니다.
Conclusion
Active learning이 인간 데이터 수집비용을 감소 시킬 수 있음 → 모델이 학습할 데이터 중 가장 정보가 많고 유익한 데이터를 선택하여, 인간 데이터 레이블러가 평가할 데이터 양을 줄임 → 적은 양의 데이터로도 효과적인 학습을 할 수 있게 하여 비용 효율성을 높임.- PRM800K를 release했음 이거로 reward model 잘 훈련시켜보셈
- process supervision은 아직 연구가 활발히 이뤄지지 않았음, 우리의 노력이 이 method의 일반화를 시키는데 일조, 앞선 길을 밝혔다고 믿음.
들어가기 전
Review를 통해 이해한 걸 바탕으로 먼저 이야기를 하면 수학 문제를 LLM이 풀 때 Reasoning Path를 생성하면서 최종 output을 생성함, 근데 이 Reasoning Path를 Solution이라고 하며 각 Solution에서 여러가지 Reasoning Path가 진행이 됨 여기서 각각의 Reasoning Path가 옳은지 PRM이라는 Classifier를 통해서 판단을 함.그래서 사실 아직 논문을 읽기 전에 던졌던 2가지 질문- How to improve the performance of the model(Generator which is making solutions)?
- How to verify the reasoning path sucessfully?
Abstract
리뷰에서 이야기한 것과 동일함. 과정에 대한 supervision을 통해서 최종 output에 대해서만 학습을 하는 것보다 더 나은 결과를 낼 수 있도록 했고 데이터셋도 공개를 한다고 함. 그리고 active learning이 뭔지는 모르겠는데 이를 통해서 과정 supervision의 효과를 상당히 많이 향상 시켰다고 함모델이 똑똑하긴 한데… 잘 모르면 hallucination을 생성해버림 → 수학을 푸는 Task 같이 Multi-step reasoning이 필요한 Task에는 굉장히 심각한 문제라고 할 수 있음 이러한 문제를 완화시키는 방법 중 Reward models에 집중함본 논문에서 사용한 방법은 ORMs (Outcome-supervised reward models)와 PRMs(process-supervised reward models) 임근데 OpenAI에서 우리가 해봄 ㅋ 해서 몇 개 바꿔서 해봤더니 너무 좋던데? 하고 contribution을 때려버림..여기서 질문 1에 대한 답이 나옴 → We do not attempt to improve the generator with reinforcement learning. 이라고함그리고 RM의 평가는 Generator 가 생성한 solutions 중에 best-of-N search로 평가를 할 거임.데이터셋 구성 → Generator가 저렇게 생성할 수 있도록 fine-tuning했음이렇게 구성한 데이터셋이 PRM800K로 12K의 문제들, 75K의 solutions 그리고 800K의 과정에 대한 human label로 이뤄져있음.전략적 솔루션 선택 : 명백하게 틀린 답을 제시하면 당연히 RM은 잘 판단할 거임. 근데 뭔가 설득력있는 정답 같은 솔루션인데 최종 답이 틀린 솔루션이 있어. 그러면 RM은 처음에는 높은 자신감으로 정답을 찍었다가 틀리니까 이에 대해서 더 많은 정보를 얻을 수 있을 것이다. 라고 주장함ORMs - Outcome-supervised Reward ModelsPRMs - Process-supervised Reward Models또 학습전략으로 첫번째 단계에서 오답을 supervision으로 넣는데 이렇게 하면 마지막 단계까지 가지 않더라도 해당 solution이 오답이라고 할 수 있어서 인간 레이블러에게 비슷한 작업 부담을 줄 수 있게 함 / 이때 추가적인 process supervision을 줌으로써 더 많은 피드백을 얻을 수 있게 한다고 함.PRM과 ORM을 학습 시킨 데이터셋이 다르다. PRM800K로 ORM을 학습을 시켰는데 이게 좋지 않았음. 따라서 PRM과 ORM의 동등한 비교는 어려움내 해석은 이렇다. 문제에 대한 solutions가 많을 수록 OPM, PRM은 본 모델들의 필요한 classify를 잘 한다. 그리고 a strong baseline이 의미하는 건 Wang et al. 2022에서 제안된 모델이다.그러면 ORM과 PRM을 같이 쓰는게 아니라 둘 중 하나만 쓰는 건가?PRM이 제일 성능이 좋음 → 왜일까? 추측을 해보면 PRM은 잘못된 reasoning이 오더라도 올바른 final answer로 도달할 수 있게 하는 solutions에 대한 더 나은 supervision을 제공하기 때문이라고 주장함위 글을 이해하면 이해할 수 있음내가 이해하기론 Active Learning이란 주어진 데이터를 그냥 학습하는 수동 학습이 아닌 주어진 데이터에서 의도에 따라서 필요한 데이터를 학습 할 수 있도록 하는 방법을 의미한다고 생각한다.
- PRMselector 훈련:
- 작은 규모의 보상 모델인 PRMselector를 각 문제당 하나의 샘플로 훈련합니다. 이 모델은 이후 각 문제당 1000개의 샘플을 평가하는 데 사용됩니다.
- 샘플 선택:
- 더 큰 보상 모델을 훈련하기 위해, 각 문제당 PRMselector에 따라 다음과 같은 비율로 샘플을 선택합니다:
- 80%: 가장 설득력 있는 잘못된 답안 샘플
- 20%: 남은 샘플 중 가장 설득력 있는 샘플 (올바르거나 잘못된 답안 모두 포함)
- 이 선택 과정은 PRMselector에 대해 상대적으로 설득력 있는 샘플들을 선택하고, 많은 샘플이 적어도 하나의 실수를 포함하도록 합니다. 또한, 전체 데이터셋이 잘못된 답안 솔루션으로 너무 편향되지 않도록 합니다.
- 더 큰 보상 모델을 훈련하기 위해, 각 문제당 PRMselector에 따라 다음과 같은 비율로 샘플을 선택합니다:
- PRMlarge로 평가 및 훈련:
- 선택된 샘플들을 PRMlarge로 평가하고 그 점수로 더 큰 보상 모델들을 훈련합니다.
- 데이터 효율성:
- Figure 4a를 통해 능동 학습을 사용한 선형 회귀선의 기울기를 비교함으로써, 능동 학습이 균일한 데이터 레이블링보다 약 2.6배 더 데이터 효율적임을 추정합니다. 즉, 능동 학습을 사용하면 동일한 데이터양으로 더 많은 정보를 얻을 수 있습니다.
- 큰 데이터셋에서의 성능 저하:
- 가장 큰 능동 학습 데이터셋(문제당 200개의 샘플)으로 훈련된 모델이 예상 경향선보다 약간 저조한 성능을 보인다고 언급합니다. 이는 전체 선택 풀(문제당 1000개의 샘플)의 상당 부분을 차지하기 때문에 다양성이 부족해져서 발생할 수 있는 현상입니다.
Discussion
설명- *Credit Assignment (신용 할당)**은 모델이 솔루션에서 발생한 오류의 원인을 식별하는 과정을 의미합니다.
- 결과 감독의 문제점: 결과 감독으로 훈련된 보상 모델은 솔루션이 틀렸을 때 어떤 단계에서 잘못되었는지를 찾아야 합니다. 이 과정은 특히 어려운 문제에서 매우 어려워집니다. 왜냐하면 대부분의 모델 생성 솔루션에는 어딘가에 오류가 있기 때문에, 부정적 레이블의 정보 가치가 낮아지기 때문입니다.
- 과정 감독의 장점: 반면, 과정 감독은 각 단계별로 피드백을 제공하여, 몇 개의 초기 단계가 올바른지와 잘못된 단계의 정확한 위치를 명확히 합니다. 이렇게 하면 오류의 원인을 정확히 파악할 수 있게 되어 모델의 신용 할당 작업이 훨씬 수월해집니다.
- 결과: 과정 감독이 더 정확한 피드백을 제공함으로써, 보상 모델이 더 잘 일반화할 수 있고, 이는 과정 감독이 결과 감독보다 성능이 뛰어난 이유를 설명합니다.
- AI 정렬은 모델이 인간의 의도와 목표에 맞게 행동하도록 하는 것을 의미합니다. AI 모델이 올바르게 정렬되었는지 여부는 그 모델의 안전성과 신뢰성에 중요한 영향을 미칩니다.
- 해석 가능한 추론: 과정 감독은 모델이 인간이 승인한 과정을 따르도록 유도하여 모델의 추론 과정을 더 해석 가능하게 만듭니다. 이는 모델이 어떻게 결론에 도달했는지를 이해하는 데 도움이 됩니다.
- 본질적인 안전성: 과정 감독은 올바른 사고 과정을 직접적으로 보상하므로, 결과를 대리자로 사용하는 것보다 더 안전합니다. 이는 모델이 인간의 가치와 목표에 맞게 행동하도록 더 잘 유도합니다.
Conclusion
Active learning이 인간 데이터 수집비용을 감소 시킬 수 있음 → 모델이 학습할 데이터 중 가장 정보가 많고 유익한 데이터를 선택하여, 인간 데이터 레이블러가 평가할 데이터 양을 줄임 → 적은 양의 데이터로도 효과적인 학습을 할 수 있게 하여 비용 효율성을 높임.- PRM800K를 release했음 이거로 reward model 잘 훈련시켜보셈
- process supervision은 아직 연구가 활발히 이뤄지지 않았음, 우리의 노력이 이 method의 일반화를 시키는데 일조, 앞선 길을 밝혔다고 믿음.
- 액티브 러닝은 액티브 러닝으로 solutions들을 선택하고 그 다음에 사람이 labeling을 함.
- AI 정렬(AI alignment)
- 이 부분은 능동 학습(active learning)을 통해 보상 모델을 훈련하는 방법과 그 효과에 대해 설명하고 있습니다.
- Active Learning
- For each dataset, we provide three forms of supervision: process supervision from PRMlarge, outcome supervision from PRMlarge, and outcome supervision from final-answer checking.
- 이제 여이거 의미하는 dataset form of supervision임 어떤 형태인지는 모르겠지만 label에 대한 dataset이라고 이해하고 있음
- 내 생각엔 PRM이 결국 여러가지 solutions 중에 best를 뽑는 거잖아? 그러니까 incorrect reasoning 이 오더라도 final answer는 정답이 오게끔 해주니까 결국 PRM으로 선택된 best-of-N solutions는 결국 correct한 answer로 도달 할 수 있게끔 해주니까 ORM, final answer something보다 성능이 더 높게 나오는 거라고 이해했음
- Process vs Outcome Supervision
- 의문점

- Large-scale Supervision
- step-level에서 정답인지 아닌지를 판단함 이때 PRM score을 사용하는데 이거롤 각 solution들이 정답인지 아닌지를 판단하는 평가 점수로 삼는다.
- 최종 output이랑 target을 비교 → true or false를 비교함
- 각 iteration 마다 problem1개에 N 개의 solution을 바탕으로 top-K 개의 convincing worng-answer 데이터를 골랐다. (data collection process가 매우 비싸 process에 대한 ablation 과정을 진행할 수 없다고 말함.)
- 그리고 오버피팅을 최소화하기 위해서 4.5K MATH test problems를 학습 데이터에 넣었
- 그래서 사람이 긍정, 부정, natural(애매함을 처리하기 위함) labeling을 할 수 있게 했음

- RM에 넣어지는 output이나 process에 대해서만 이야기할 거임.
- Method
- ORM은 최종 output을 사용하는 거고 PRM은 중간 과정 즉, reasoning path를 사용해서 결과를 내게 하는 거임. 기존에 Uesato et al. (2022)가 이걸 먼저 실험했는데 ORMs + PRMs 둘 다 사용한 거랑 ORMs 하나만 사용한 거랑 별 차이가 없다고 주장했음
- 심플하게 이야기하면 이 RM은 hallucination이 발생하지 않은 output을 선택할 수 있게 도와줌
- Introduction & 본 논문의 Motivation
- 그래서 리뷰를 좀 더 읽어보고 그리고 논문을 좀 더 읽어보면서 생각을 해봐야 할듯 함.
- 그렇다면 해당 논문에서 제안하는 건 어떤 Solution에 대한 개선보다는 더 좋은 Solution을 선택하는 Classifier를 제안하는 건가? 하는 생각이 들었음
- 액티브 러닝은 액티브 러닝으로 solutions들을 선택하고 그 다음에 사람이 labeling을 함.
- AI 정렬(AI alignment)
- 이 부분은 능동 학습(active learning)을 통해 보상 모델을 훈련하는 방법과 그 효과에 대해 설명하고 있습니다.
- Active Learning
- For each dataset, we provide three forms of supervision: process supervision from PRMlarge, outcome supervision from PRMlarge, and outcome supervision from final-answer checking.
- 이제 여이거 의미하는 dataset form of supervision임 어떤 형태인지는 모르겠지만 label에 대한 dataset이라고 이해하고 있음
- 내 생각엔 PRM이 결국 여러가지 solutions 중에 best를 뽑는 거잖아? 그러니까 incorrect reasoning 이 오더라도 final answer는 정답이 오게끔 해주니까 결국 PRM으로 선택된 best-of-N solutions는 결국 correct한 answer로 도달 할 수 있게끔 해주니까 ORM, final answer something보다 성능이 더 높게 나오는 거라고 이해했음
- Process vs Outcome Supervision
- 의문점
- Large-scale Supervision
- step-level에서 정답인지 아닌지를 판단함 이때 PRM score을 사용하는데 이거롤 각 solution들이 정답인지 아닌지를 판단하는 평가 점수로 삼는다.
- 최종 output이랑 target을 비교 → true or false를 비교함
- 각 iteration 마다 problem1개에 N 개의 solution을 바탕으로 top-K 개의 convincing worng-answer 데이터를 골랐다. (data collection process가 매우 비싸 process에 대한 ablation 과정을 진행할 수 없다고 말함.)
- 그리고 오버피팅을 최소화하기 위해서 4.5K MATH test problems를 학습 데이터에 넣었
- 그래서 사람이 긍정, 부정, natural(애매함을 처리하기 위함) labeling을 할 수 있게 했음
- RM에 넣어지는 output이나 process에 대해서만 이야기할 거임.
- Method
- ORM은 최종 output을 사용하는 거고 PRM은 중간 과정 즉, reasoning path를 사용해서 결과를 내게 하는 거임. 기존에 Uesato et al. (2022)가 이걸 먼저 실험했는데 ORMs + PRMs 둘 다 사용한 거랑 ORMs 하나만 사용한 거랑 별 차이가 없다고 주장했음
- 심플하게 이야기하면 이 RM은 hallucination이 발생하지 않은 output을 선택할 수 있게 도와줌
- Introduction & 본 논문의 Motivation
- 그래서 리뷰를 좀 더 읽어보고 그리고 논문을 좀 더 읽어보면서 생각을 해봐야 할듯 함.
- 그렇다면 해당 논문에서 제안하는 건 어떤 Solution에 대한 개선보다는 더 좋은 Solution을 선택하는 Classifier를 제안하는 건가? 하는 생각이 들었음



댓글