"어떤 Input을 넣느냐에 따라 너의 뇌가 바뀐다"
읽고 난 후
먼저 정리를 해보자면 LiDAR은 비쌉니다. 그래서 맨 처음 Image를 기반으로 depth map을 예측해서 3D Object Detection을 하는 방법이 나왔지만 Convolution Network에서 2가지 문제점(1. 인근 pixel을 동일한 깊이로 인식한다 2. 멀리있는 객체를 가까운 객체로 인식한다)를 가지고 있어서 실제 LiDAR에 비해 정확도가 많이 떨어진다고 합니다. 그런데 논문에서는 정확도가 낮은 이유는 data의 quality가 아니라 data 의 representation의 문제라고 말합니다. 여기서 representation이 뭐냐면 data를 가지고 예측을 때릴 때 사용되는 기법이라고 생각하면 좋을 거 같습니다. 그니까 어떤 방식으로 주어진 data를 처리하고 어떤 형태의 데이터로 예측을 하느냐. 이게 중요한 것이다.라고 하네요.
그래서 본 논문에서 제안하는 방법은 다음과 같습니다. 먼저 image에서 depth estimation을 통해서 depth map을 만듭니다. 그래서 이를 어떤 공식에 넣어 Pseudo LiDAR Data를 만듭니다. 이를 가지고 실제 LiDAR 데이터를 넣어 진행하는 3D object detection 알고리즘에 넣습니다. 그리고 3D Boxed로 예측을 진행합니다.
이 결과는 imaged-based보다 확실히 좋지만 실제 LiDAR만큼 좋지는 않습니다. 그래서 추후 과제로 이 간극을 줄이는 걸 문제를 남겼습니다.
먼저 다른 분의 의견을 보면 본 논문에서 성능 비교를 위해 사용한 알고리즘인 Monocular image, Stereo image에서 Stereo image 를 사용할 때 더 정확한 depth map을 추출할 수 있기 때문에 data representation의 문제만이라고 할 수 없다고 이야기합니다.
저는 이 논문을 읽으면서 생각했습니다. 제 관심 분야가 아니고 과제 때문에 읽는 논문이었지만 제가 논문 한편을 다 읽을 수 있는 사람이었구나를 알게 되었고 또 논문에 나온 내용에 대한 코드를 구현할 수 있도록 해야겠다는 생각이 들었습니다.
본 논문을 시작으로 수많은 논문을 읽고 정리할 생각을 하니 가슴이 아픈게 피곤한 건지 설레는 건지 아직은 잘 모르겠습니다. 이상입니다.
논문을 읽게 된 배경 : Pseudo-LiDAR 연구실 과제를 해결하기 위해 공부 목적으로
Abstract
자율주행에서 3D object detection은 필수적인 과제입니다. LiDAR를 통해서 얻은 데이터는 정확하지만 비쌉니다. 그래서 이미지나 monocular data는 싸지만 정확도가 현저하게 낮습니다. 그리고 그 차이가 생기는 이유는 image-based depth estimation이 부족하기 때문이라고 한다. 하지만 이 논문에서는 데이터의 질이 문제가 아니라 이것의 문제는 데이터가 나타나지는 방식이 문제라고 이야기합니다.
그래서 우리는 imaged-based depth한 지도들을 pseudo-LiDAR representations로 변환시키는 걸 제안하며 이 방법은 기존의 존재하는 LiDAR-based한 detection 알고리즘과 다릅니다. (다른 알고리즘에 해당 데이터를 넣어서 진행한다는 뜻 같습니다.)
KITTI 데이터셋을 사용했으며 현존하는 기술 중 최고의 detection 정확도를 가집니다.
Introduction
3D object Detection이 중요한 이유는 자율주행인 차가 어떤 객체와의 충돌을 피하기 위해서입니다.
정확도가 높은 LiDAR가 있지만 대체품을이 계속 나오는 이유는 여러가지가 있습니다.
1. LiDAR는 비싸다.
2. 하나의 센서에 과도하게 의존하는 건 안전 문제가 있고 이에 문제가 있을 시 사용할 수 있는 2번째 센서를 백업용으로 사용하는게 좋을 수도 있다. 그래서 2번째 센서를 Optical cameras를 사용한다. 이 카메라는 싸고 좋다.

지금까지의 논문은 monocular와 stereo depth estimation으로 3D objefct detection을 연구했지만 결국 지금까지 LiDAR 의 정확도 level까지 성공하지 못했습니다.
우리 실험은 stereo depth estimation의 error가 이차원적으로 증가했지만 시각적인 비교를 했을 때 3D point clouds가 LiDAR이 만드는 것과 stereo depth estimator가 만드는 게 높은 질적인 match를 가지는 걸 보여주었습니다.
이 논문에서 우리가 가지는 가정은 stereo와 LiDAR사이에 성능 차이가 나는 주요 원인은 depth 정확도에서 불일치해서가 아니고 stereo 에서 사용되는 3D object detection(ConvNet을 기반으로한)에서 3D 정보의 잘못된 representations의 선택이라는 것입니다.
왜냐 LiDAR의 경우 bird's-eye view의 관점에서 위에서 아래를 보는 식으로 object의 shapes나 size가 변하지 않지만 image-based depth는 밀집된 pixel 단위로 측정되고 추가적인 이미지 채널로 표시되서 멀리 있는 objects를 더 작게 그리고 detect하기 어렵게 만들기 때문입니다. 심지어 3D 공간에서 멀리 떨어져 있는 객체를 pixel 주변에서는 가까이 있는 것으로 그룹화 할 수 있기 때문에 convolutional network(이런 채널에서 2D convolutions에 의존하는) 가 3D Object를 reason(추론)하고 정확하게 지역화하는 걸 어렵게 만듭니다.
아무튼 우리의 주장을 평가하기 위해서 2가지 단계를 소개합니다. (for stereo-based 3D object detection)
1. stereo or monocular 이미지를 LiDAR 신호와 유사하도록 한 pesudo-LiDAR이라고 언급한 3D point cloud로 변환합니다.
그리고 바로 pesudo-LiDAR representation에서 학습을 시킵니다. 3D depth representation을 pseudo-LiDAR로 바꾸면서 우리는 전에 없던 정확도 증가를 얻을 수 있습니다.
the use of pseudo-LiDAR representation can still lead to significant improvements in accuracy
니다. 그렇습니다. 요는 pseudo-LiDAR representation이 제일 중요하다.
결론적으로 이 논문에서 진행한 실험은 2가지에 영향을 미쳤는데 하나는 stereo-based 와 LiDAR-based 3D object detection에서 중요한 건 representation이라는 것과 pseudo-LiDAR을 새로운 방식으로 제안해서 최고의 성능을 보이였고 이러한 결과들은 자율 주행차량에서 안전은 증가시키고 비용을 감소시키는 결과를 내게 할 거다. 라는 거다.
Approach
기존 생각 => LiDAR 같은 Time-of-Flight 접근법과 다르게 stereo-based 3D depth estimation은 물리적으로 차이가 나기 때문에 발생한다고 생각했다. 그런데 우리는 다르게 주장한다. 차이가 발생하는 이유는 data representation이라고. 실제로

Figure 1 에서 볼 수 있듯 최근 알고리즘은 놀라울 정도로 정확도 높게 depth map을 잘 만들 수 있게 한다.
우리가 진행한 2단계는 아래와 같다.
stereo image에서 촘촘한 pixel 깊이를 추정하고 3D point cloud로 픽셀들을 back-projecting합니다. 그렇게 얻은 pseudo-LiDAR 신호를 representation으로 생각하고 이를 실제 LiDAR 알고리즘에 적용시킵니다.
그니까 image를 Depth Map으로 추정하고 이를 back-projecting해서 만든 pseudo-LiDAR 의 데이터를 가지고 실제 LiDAR 알고리즘에 적용시킨다.
Depth estimation
다른 깊이 추정 알고리즘에 구애 받지 않는다.
그 전에 Depth Map을 만들 때 알아야 하는 깊이 추정 방식이 있는데 아래와 같다
스테레오 비전 (Stereo Vision)
: 스테레오 비전은 두 개의 카메라를 사용하여 3D 정보를 추출하는 가장 일반적인 방법입니다. 이러한 카메라 배열은 인간의 두 눈처럼 작동하며, 두 이미지 사이의 차이 (불일치)를 이용하여 깊이 정보를 계산합니다.
본 논문은 2개의 이미지를 가지고 baseline을 주고 input image와 같은 해상도의 disparity map을 만들고 이 disparity map을 통해서 Depth Map을 만듭니다. 이 Depth Map을 만드는 식이 아래와 같습니다.

여기서 u,v 는 이미지의 좌표를 의미하고 fu는 초점의 거리, b는 두 이미지 사이에서 baseline의 거리를 의미하고 두 이미지 사이의 차이를 Y(u,v)로 표시합니다. 이때 fu는 렌즈와 이미지 센서사이의 커리를 의미합니다. 측정하는 단위가 달라진다 정도 생각하시면 좋을 거 같습니다.

이를 이해하기 위한 그림은 위와 같습니다. 완벽하게 이해하지는 못하겠지만 두 장의 이미지를 서로 비교해서 disparity map을 만들고 이 disparity map을 통해서 Depth Map을 구할 수 있다고 합니다.위 삼각형의 비를 이용한다고 하네요.
Pseudo-LiDAR generation
이제 Depth Map을 이용해서 3D point cloud를 만들어야 겠죠.
기존에는 RGB 에 depth D를 새로운 채널에 추가했다면 이 논문에서는 각각의 픽셀 u,v에 3D location인 (x,y,z)를 도출했다.
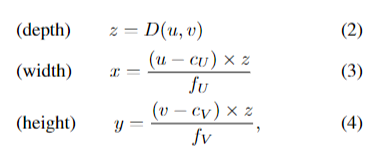
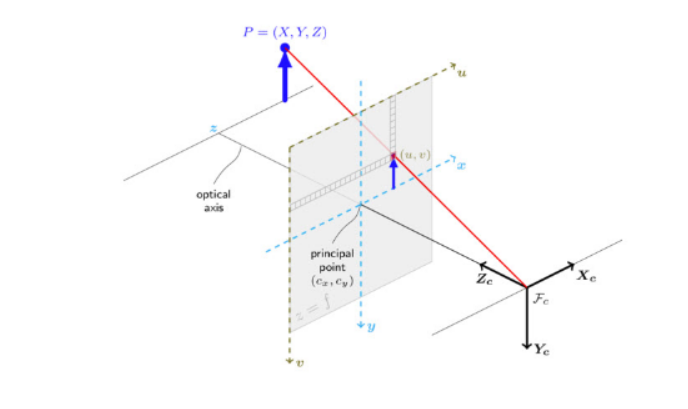
음... 삼각비를 통해서 이차저차 해서 Back-projection이 가능합니다. 그래서 이렇게 나온 값을 pseudo-LiDAR 신호라고 합니다.
LiDAR vs pseudo-LiDAR
pseudo-LiDAR를 LiDAR와 최대한 비슷하게 하기 위해서 몇 가지 post-processing을 pseudo-LiDAR에 적용했습니다. 실제 LiDAR는 특정 높이에서 측정되기 때문에 pseudo-LiDAR에서 범위를 벗어난 데이터를 삭제해줍니다.
또한 LiDAR는 reflectance라는 정보를 가지고 있습니다.
→ reflectance는 LiDAR가 반사된 정도를 의미합니다.
그런데 reflectance 데이터가 없어서 그냥 간단하게 1.0으로 정해놓았다고 하네요. (이게 뭐더라 그 아 뭐였지 당연한 가정?? 암튼 이유가 없는 부분으로 지적 받을 수 있겠네요)
그런데 차나, 보행자 같은 우리가 대부분 측정해야 하는 대상은 해당 범위를 벗어나지 않기 때문에 정보 손실은 거의 없다고 할 수 있다고 합니다.
암튼 이를 통해 구한 pseudo-LiDAR는 figure 1 에서 나타난 거 같이 LiDAR와 거의 차이가 없었다고 합니다.
이때 어떤 LiDAR의 특성에 주목했는데 같은 순서인 장면에 100,000 포인트 이상 캡처를 하지만 이 포인트들이 몇 개의 수평 beam에 따라 분포 되며 3D 공간을 드문드문 차지한다는 특성입니다.
3D object detection
이렇게 구한 pseudo-LiDAR point들은 LiDAR로 구한 point를 적용하는 알고리즘에 적용시킬 수 있다. AOD와 pointNet을 사용했다.
1. pseudo-LiDAR 정보를 3D point cloud로 다룬다. (PointNet은 2D object detections을 3D로 바꿔준다) 그리고 3D point cloud를 frustum PointNet에 적용시킨다. (이걸로 3D frustum에서 point-set features를 추출한다)
2. pseido-LiDAR 정보를 Bird's Eye View로 본다. 위에서 아래를 보는 방식에서 2D image로 3D 정보가 변환된다. 너비와 깊이가 공간 치수가 되고 높이는 채널들에 저정된다. AVOD는 시각 기능과 BEV LiDAR 기능을 연결합니다
3D 박스 프로포절을 유도한 다음 박스 분류 및 회귀를 수행하기 위해 둘 다 융합합니다
AVOD: RGB image와 LiDAR를 사용하는 model, high resolution feature를 fusion하고 이후 second stage에서 proposal들에 대한 feature 끼리 한번 더 fusion을 하는 방식
Data representation matters
이쪽에서는 pseudo-LiDAR가 depth map이랑 같은 정보를 전달하지만 즉 이미지와 같은 정보를 전달하지만 3D object detection pipline에 왜 더 적합한지에 대해 설명합니다.
먼저 convolutional network 는 2D convolutions 연속을 수행합니다. filter들이 학습이 가능하지만 주요 가정은 2가지 입니다.
a. 인근에 있는 pixel들은 어떤 의미를 가지고 있고 그들을 지역 patches로 봐야한다. 즉 서로 가까운 pixel들은 의미를 가지고 있고 하나의 patch에 존재한다는 것입니다.
b. 그리고 해당 인근에 있는 pixel들은 동일한 방법으로 연산될 수 있다는 겁니다. 즉 3D에서는 멀리 떨어져 있지만 2D에서는 인근에 있기 때문에 동일한 연산을 가져갈 수 있다는 것입니다.
그리고 위 가정들은 완벽하지 않은 것들이다. 라고 합니다.
그래서 기존 2D image를 통해 object detection을 하는 방법은 위와 같은 가설들을 해결하려고 노력했지만 쉽지 않았다. 는 거고 그래서 2D convolution은 적합하지 않다고 합니다.
대조적으로 3D convolutions는 bird's eye view에서, 물리적으로 가까운 pixel들에서 작동합니다. 이로써 서로 떨어져 있는 물체들에 대해 같은 크기라는 걸 알 수 있고 멀리 있는 물체와 가까이 있는 물체를 같은 방법으로 다룰 수 있게 됩니다. 이런 연산은 물리적으로 의미가 있고 또 너 나은 학습과 더 좋은 정확성을 가진 모델을 나타내게 합니다.

Convolved를 보면 이미지에서 인근한 pixel을 같은 depth라고 인식할 수 있기 때문에 본래의 box보다 더 길게 box가 나타난 걸 알 수 있습니다. 하지만 Convolved를 사용하지 않았을 때 실제 depth를 잘 표현하는 걸 볼 수 있습니다.
Experiments
여러 가지 실험을 진행했고 실험 결과는 depth estimation과 object detection이다. pseudo-LiDAR로 얻은 결과를 파란색으로 LiDAR로 얻은 결과를 회색으로 표기하겠습니다.
Dataset.
KITTI object detection benchmark
Metric.
focus on 3D, bird's-eys-view
Details of our approach
- PSMNet (Pyramid Stereo Matching Network): end-to-end로 복잡하게 놓인 사물도 정확한 stereo matching 점을 찾아 후처리 없이 depth map을 생성하는 모델
- DispNet: 가상의 data로도 잘 동작하는 모델, large dataset에서 최초로 학습 가능한 convolutional network
같이 여러 모델을 사용했으면 fine-tuning도 진행했습니다. 그런데 실험 중에 KITTI stereo 2015에 있는 200개의 학습 이미지가 검증 이미지와 겹쳤었고 KITTI 대신에 Scene Flow(3,712개)를 사용했습니다. 그렇게 하니까 더 나은 결과를 보였습니다. 이를 통해서 더 큰 dataset을 사용하는게 PSMNet 정확도 향상을 가져온다고 할 수 있었다고 합니다.
Monocular depth estimation
현재 최고의 depth estimator인 DORN을 사용
Pseudo-LiDAR generation.
우리는 제공된 보정 행렬을 사용하여 추정된 깊이 맵을 Velodyne LiDAR 좌표계의 3D 포인트로 역투영합니다.
3D Object detection.
F-POINTNET-v1 과 AVOD-FPN을 적용 여기에 LiDAR 데이터 대신 pseudo-LiDAR를 넣어서 3,712 학습 데이터를 학습시칸다. We note that AVOD takes image-specific ground planesas inputs.
여기서 말하는 image-specific ground planesas는 특정 이미지에 연관된, 즉 그 이미지를 촬영한 카메라의 시점에서 정의된 지면 평면을 나타낸다
이걸 얻는 방법이 RANSAC이라는 straight-forward application인데 자세한 사항은 Supplementary Material에 있다.
Experimental results
DORN은 PSMNET보다 거의 10배 많은 이미지(및 일부는 검증 데이터와 중복됨)로 훈련되었지만 PSMNET과의 결과가 지배적입니다. 이는 스테레오 기반 탐지가 특히 스테레오 카메라의 경제성 증가를 고려할 때 유망한 방향임을 시사합니다.
monocular depth (DORN)
Impact of data representation
이제 알겠다. data representation이란 뭐냐면 예전에는 그저 image-based한 방법으로 3D point cloud를 구했는데 이게 정확도가 낮더라. 그러니까 여기서 image-based로 그냥 구하지 말고 데이터 representation 그러니까 데이터를 나타내는 방법을 달리 해보자. 그래서 나온게 psedo-LiDAR. PointNet과 AVOD를 통해서 image를 depth map으로 바꾸고 이걸 psedo-LiDAR로 바꾼다. 그러면 이걸로 실제 LiDAR 값을 넣는 알고리즘에 넣으면 겁나 비슷하게 값이 나온다는 것. 이런 방식을 통해 data의 질이 아니라 data representation이 잘못된 거다. 라고 주장한 것.
MLF-STEREO는 CNN을 이용해서 map에 대한 좌표를 RGB 채널에 덧붙여서 사용한 알고리즘이다. 이렇게 하니 위에서 언급했던 2가지 문제가 발생한다. 그래서 AP_BEV와 AP_3D가 낮다.
대조적으로 우리는 그 좌표들을 pseudo-LiDAR신호로 다루고 이를 PointNet이나 AVOD에 적용한다
Table 2를 보면 알겠지만 disparity estimation(두 이미지 에 있는 물체 위치에 차이)의 정확도가 물체 탐지의 정확도와 어떤 상관관계가 있는 걸 아니다는 걸 보여준다. 그래서 이 disparity estimation을 통해서 depth estimation을 진행하는데 만약에 disparity error가 발생하면 그만큼 depth error 또한 나타날 수 있다.
남은 질문은 어떻게 pseudo-LiDAR를 실제 LiDAR 신호랑 가깝게 하느냐이다.
Pedestrian and cyclist detection
이런 object를 식별하는 건 실제 LiDAR에서도 task다. 크기가 작기 때문에 정확도가 확 떨어지는 걸 볼 수 있다.

Results on the test set
Car 종류에서의 결과 Table을 놓겠다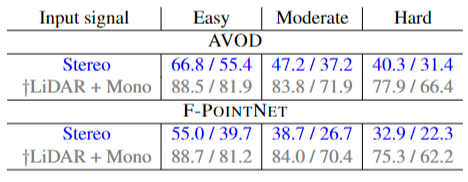
Validation data에서 차이가 LiDAR만큼 난다고 하는데 그런가? 싶습니다. 차이가 많이 나는 거 같긴하지만 아무튼 그렇답니다. 그리고 KITTI learderboard에서 image-based 알고리즘 중에 짱이라고, 1등을 먹을 거라고 합니다.
Visualization

그 결과를 위와 같이 표기합니다.
Discussion and Conclusion
본격적인 자랑의 시작. + 실제 LiDAR에서도 imaged-based가 사용될 수 있고
이러한 비약적인 발전으로 자율 주행 차량에 대한 이미지 기반 3D 물체 감지가 가까운 미래에 현실화될 가능성이 높습니다
라고 합니다. LiDAR 하드웨어는 자율 주행 차량의 하드웨어 중에 가장 비싸며 만약에 이 기기가 빠지면 상대적으로 다른 추가적인 하드웨어는 작다고 할 수 있다. image-based가 발전되면 실제 LiDAR를 사용하더라도 이를 활용하면 이득이 될 수 있습니다. 아니면 하드웨어가 고장났을 때 backup 용으로 사용될 수도 있습니다.
Future work
더 향상이 될 방법이 있다.
고해상도 stereo 이미지가 상당히 먼 거리에 있는 물체의 정확도를 높일 수 있다. 현재 이 논문에서 진행한 데이터는 0.4megapixels을 사용했는데 이는 최신 카메라 기술과는 거리가 (a far cry from) 먼 실정이다.
둘째로 현재 논문에서는 실시간 이미지 처리에 초점을 맞춘게 아니라서 해당 방법은 즉각적인 객체 detection 을 요구하는 app에 적합하지 않을 수 있다. 그리고 하나의 이미지에서 모든 객체를 분류하는 건 1초 언저리가 걸리는데 이는 실시간 처리와 비교하면 상대적으로 느리다고 할 수 있습니다. 이런 속도를 몇 배나 향상 시킬 수도 있습니다.
마지막으로 추후 과제는 LiDAR와 pseudo-LiDAR 센서를 합침을 통해 3D object detection을 향상 시킬 수 있습니다.
우리의 이 진전이 cv에서 image와 LiDAR의 차이를 완전히 줄이는 부분에 이바지할 것입니다.
라고 하면서 본 논문은 마무리 되고 Supplementary Material이 나옵니다.
'AI 관련' 카테고리의 다른 글
| MoE(Mixture of Experts) by hugging face (0) | 2025.01.22 |
|---|---|
| 'Adam'보다 더 빠른 옵티마이저 등장? by 스탠포드 대학 (0) | 2023.06.05 |

댓글